Whoa, it’s about time to talk about accuracy and precision in terms of SOPARE. SOPARE is a Python project that listens to microphone input and makes predictions from trained sounds like spoken words. Offline and in real time.
Before we go into the details we make a quick excursion how SOPARE is processing sound. The microphone listens permanent and records every sound in small chunks. As soon as the volume of a sound reaches a specified threshold, SOPARE adds some small chunks and creates a bigger chunk. At this time, SOPARE has an array of data in raw mic input format. The input receives some filtering (HANNING) and the time domain data is transformed into the frequency domain. Now SOPARE removes unused frequencies as specified in the configuration (LOW_FREQ and HIGH_FREQ).
At this stage SOPARE is able to compress the data (MIN_PROGRESSIVE_STEP, MAX_PROGRESSIVE_STEP). Compression is a big factor of precision. Progressive steps mean that a number of frequencies are combined into one value. A progressive step of 100 takes 100 values and creates one (1) combined value. This is a very rough preparation and a good way to create lots of false positives. The opposite would be a step of one (1) which would use each frequency for the characteristic and prediction and represents the max. accuracy – but maybe also the worst true positive recognition.
This is how the process looks like. From the full blown time domain data (40000), to the specified number of frequencies (600) and at the end there is a compressed set of data (24) which is quite clear and used for the predictions.
You need to test around and find some good values for your setup and environment. If you have optimal values, train your sound patterns.
Please note that the values in the section “Stream prep and silence configuration options” must be used for training and whenever you change them you need to do a new training round. This means remove the trained files via
mv dict/*.raw /backup
or
rm dict/*.raw
and train again!
Now let’s talk about options to enhance precision and accuracy. First of all, you should note that one identifier is always susceptible for false positives. Checking for two or more patterns/words increase the precision big time.
The second option is to make use of the config options to increase the accuracy. Let’s start with the one that identifies a word or pattern:
MARGINAL_VALUE
The marginal value can have a range between 0 and 1. Zero (0) means that everything will be identified as the beginning of a word, 1 means that the trained sample and the current sound must match 100%. Good values lie between between 0.7 and 0.9. Test around how high you can increase the value while still getting real results. For testing purpose keep this value quite low.
MIN_CROSS_SIMILARITY
is the option that is used for comparison. Again, 0 means everything is a match and 1 means that the trained pattern and the current sound must match 100%. For one word scenarios, this value can be quite high, two or more words require normally lower values as the transitions from two patterns are most likely not as single trained words. Good values in my setups are between 0.6 and 0.9. 0.9 for single words, lower values for multiple word recognition.
The following values have a huge impact but I can’t hand out best case values. Instead, they require some manual testing and adjustment:
MIN_LEFT_DISTANCE MIN_RIGHT_DISTANCE
These values are somehow special. For each word/pattern SOPARE calculates the distance from the trained word and the current sound. A low distance means that the characteristic is similar, high distances means that there is a difference. Left and right means that the frequency ranges are halved and the lower and higher bandwidth is compared respectively. Even if a prediction for the whole word is very close, even a small distance can be essential to filter out false positives. The debug option reveals the most important values:
sorted_best_match: [[MIN_CROSS_SIMILARITY, MIN_LEFT_DISTANCE, MIN_RIGHT_DISTANCE, START_POS, LENGTH, u'PREDICTION'], [MIN_CROSS_SIMILARITY, MIN_LEFT_DISTANCE, MIN_RIGHT_DISTANCE, START_POS, LENGTH, u'PREDICTION']]
Again, this requires some fiddling around to find the optimal values that gives true positive and avoid the false ones…start with high values and reduce until you are satisfied. In my smart home light control setup the values are around 0.3 and my false positive rate is near zero although SOPARE is running 24/7 and my house is quite noisy (kids, wife, …).
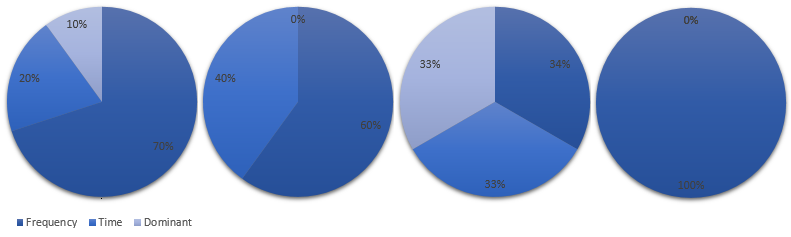
The last config options to consider is the calculation basis for the value “MIN_CROSS_SIMILARITY”. The sum of the three following values should be 1:
SIMILARITY_NORM SIMILARITY_HEIGHT SIMILARITY_DOMINANT_FREQUENCY
“SIMILARITY_NORM” is the comparison of the FFT similarity.
“SIMILARITY_HEIGHT” compares against the time domain shape. Good if you want to consider a certain volume.
“SIMILARITY_DOMINANT_FREQUENCY” is the similarity factor for the dominant frequency (f0).
I recommend to play around with this values and learn the impacts. Based on the environment, sound and the desired outcome there are plenty of possible combinations. Here are some examples:
Puuhhh, this post got longer than expected and the videos have also 25 minutes content. Hope I got everything covered:
Part 1:
Part 2:
Part 3:
Part 4:
That’s it. If you have questions or comments don’t keep back and let me know 😉
As always, have fun and happy voice controlling 😉