More than a year ago I’ve written about voice controlled stuff. Enterprise NCC-1701-D like. As you all know: with the rise of cloud APIs this can be accomplished with some work. Downside is that all your talks will be processed in the cloud which means that you may lose your privacy. As I like the Raspberry Pi my goal was to have something running locally on a Pi. To be more specific: on a Raspberry Pi 2. After trying Jasper and some other projects my personal conclusion was that the small device is not powerful enough for the heavy lifting. This said I just want instant results. And I want to talk from anywhere in the room. I don’t care where the microphone is located. So I started the project SoPaRe to figure out what is possible. My goals were (and still are):
- Real time audio processing
- Must run on small credit card sized, ARM powered computers like Raspberry Pi, Banana Pi and alike
- Pattern/voice recognition for only a few words
- Must work offline without immanent dependencies to cloud APIs
- Able to talk free from anywhere in a room
I must admit that I did not expect much trouble as it’s only data processing. Well, I changed my view and learned a lot. My current result is a first usable system that is able to learn sounds (in my case words) and recognize them even when I not talk directly in the microphone but from 2 meter away and from different angles. But let’s start with some basics. The following image shows the printed result of me saying three words: “computer light off”.
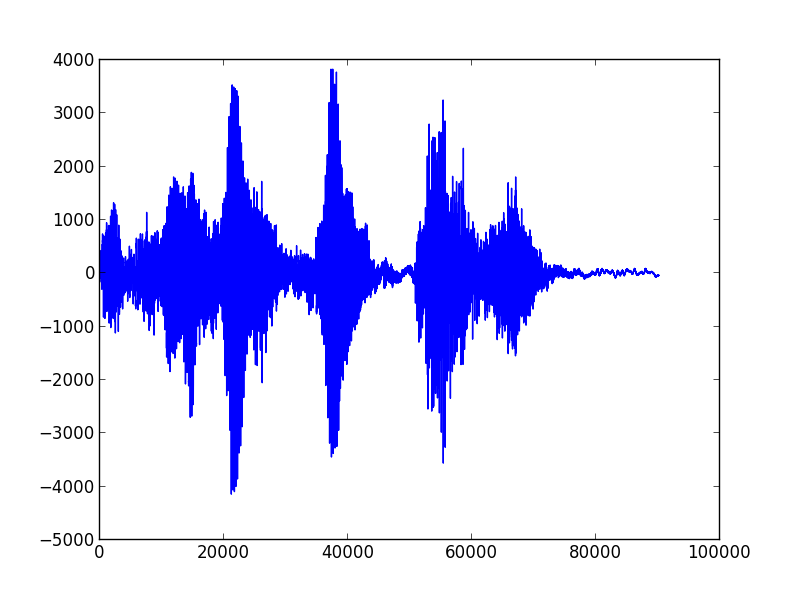
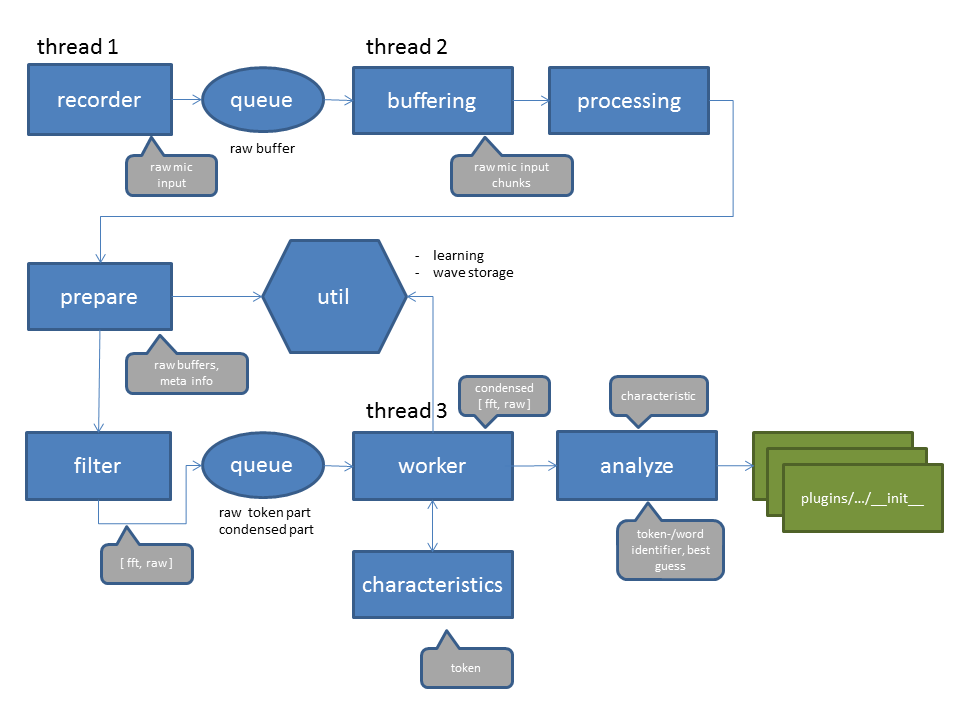
In memory we talk about 80000 values that are generated in roughly 3 seconds. As one of my primary goals was real time processing this number is huge. As the Raspberry PI 2 has 4 cores one of my first decisions was to leverage real threads and process the data on different cores to get a good throughput. Another broad idea was to crunch the data and work with just a small characteristic of the sound. This diagram shows the current project architecture:
First of all we have to “tokenize” a sound into small parts that can be compared. Like single words from a sentence:
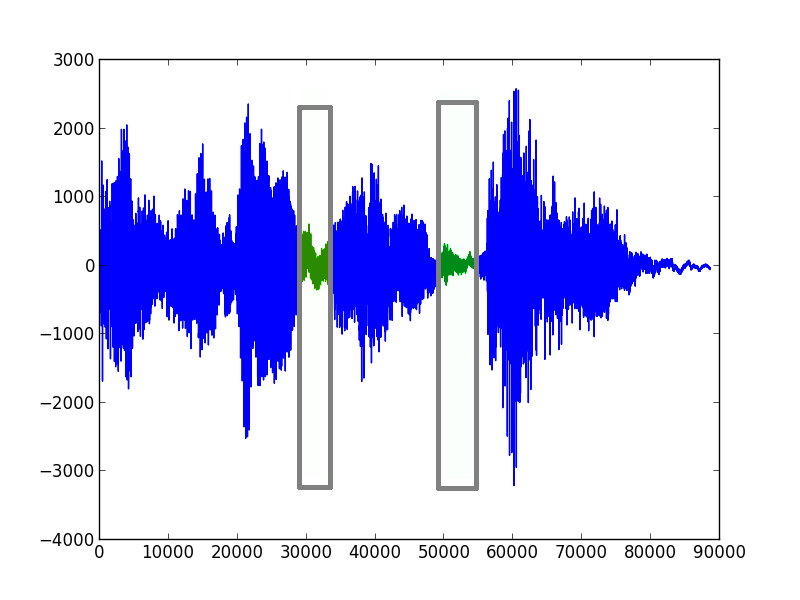
In the current version even a single word is parted into smaller parts like “com-pu-ter” and for all this parts a characteristic is generated. These characteristics can be stored for further comparison. I tried quite some stuff but I get decent results with a combination of a condensed fast Fourier transformation and rough meta information like length and peaks.
The current version is able to not only match learned words in a sentence but also does this is a real environment. This means standing in a room and the microphone is somewhere located in the corner. Or speaking from quite a distance. On the other hand I still get false positives as the approach is rough. But I’m quite happy with the current state that’s why I talk about it now. The project (SoPaRe) incl. the source code is located on GitHub. Happy to receive your feedback or comments and of course, if you are using SoPaRe, please tell me about it!
My next step is to kick off the beta testing and enhance here and there. Will write again when we have more results after the test phase 🙂
Hi, great work so far. I need something like this just to detect a keyword and then do speech to text using houdify or google speech.
Can you please tell me the steps to take to teach and detect the word ‘hallo’ using your sopare program? I tried different combinations of the arguments but don’t get any results.
Also I do get this error when running:
start endless recording
Process buffering queue:
Traceback (most recent call last):
File “/usr/lib/python2.7/multiprocessing/process.py”, line 258, in _bootstrap
self.run()
File “/home/magnus/sopare_app/sopare/buffering.py”, line 44, in run
self.proc.check_silence(buf)
File “/home/magnus/sopare_app/sopare/processing.py”, line 85, in check_silence
self.stop(“stop append mode because of silence”)
File “/home/magnus/sopare_app/sopare/processing.py”, line 54, in stop
self.prepare.stop()
File “/home/magnus/sopare_app/sopare/prepare.py”, line 75, in stop
self.filter_reset()
File “/home/magnus/sopare_app/sopare/prepare.py”, line 92, in filter_reset
self.filter.reset()
File “/home/magnus/sopare_app/sopare/filter.py”, line 42, in reset
self.queue.put({ ‘action’: ‘reset’ })
File “/usr/lib/python2.7/multiprocessing/queues.py”, line 100, in put
assert not self._closed
AssertionError
Buffering not alive, stop recording
stop endless recording
Python 2.7.6, Ubuntu 14.04
Thanks
Hi, sure. First please make sure to update to the last version of SoPaRe!
Next you should find out the noise level for your environment and microphone. You simple do this by running
./sopare.py -l -v
and adjusting the config setting “THRESHOLD” in the “file sopare/config” in the way that no debugging output shows up until you say the trigger word. When you say the word, debugging output must be show up. “CTRL-c” to stop.
After finding and adjusting the normal conditions you start the training. Do this by starting the training mode with the command
./sopare.py -t hello
Quite conditions work best to do the training. Say the word shortly after the line “start endless recording” appears on the screen. Repeat this 3-5 times.
Whenever you finished the training round, run
./sopare.py -c
and create a working model of your training data.
You can test the model by running
./sopare.py -l
and saying your trained word.
That’s it. A video tutorial with more examples and background information is on the way but I need some more weekends to finish this so please stay tuned.
Have fun!
Thanks,
I have tried these steps and it has worked. I do get false positives as you mentioned, but I believe it is a step in the right direction. I think words with similar lengths will always give false positives as there are generally the same frequency components in one’s voice (FFT will give same results), but I might be wrong.
You are welcome,
and excellent that it works. In terms of false positives: you can increase the thresholds of the minimal similarity margins to get “better” results. But, the current implementation has limits due to the rough data assembling. My current testing branch has some improvements to this regards – so make sure to pull the changes when they are available 😉
hi
please I want to know the length of the trained wards. what is the maximum length of each trained ward in seconds?
Hi. There is no max. length of a word. But there are several config options that are related to training and recognition such as MAX_SILENCE_AFTER_START, MAX_TIME and LONG_SILENCE
There is a short docu within the config file and you should get an understanding when you play around with the values.
Hallo,
ich habe den Eindruck, wir können uns auch auf deutsch unterhalten.
Ich habe da eine Fehlermeldung samt Ursache(?). ich wollte nur wissen, wird SoPaRe noch gepflegt? Dann würde ich meine Erkenntniss weitergeben, ansonsten hätte ich die Frage: Welche handhabbare Voice Recognition gibt es noch? Deine Entwicklung, Doku, YouTube’s gaben (für mich zum ersgen Mal) die Info, wie es dnach weitergehen kann. Siehe plugin __init_.py.
Viele Grüße
Andreas
Hi. Ja, SOPARE wird weiter gepflegt. Aktuell werden zwar nur Fehler behoben, aber ss gibt auch neue Punkte die ich gerne angehen würde – da kann ich allerdings nicht sagen wann ich dazu komme. Bugs/Issues/Fehler bitte via GitHub melden, denn dafür ist das Forum nicht geeignet.
Eine aktuelle Übersicht der Tools habe ich auch nicht zur Hand, da hilft nur suchen 😉