More than a year ago I’ve written about voice controlled stuff. Enterprise NCC-1701-D like. As you all know: with the rise of cloud APIs this can be accomplished with some work. Downside is that all your talks will be processed in the cloud which means that you may lose your privacy. As I like the Raspberry Pi my goal was to have something running locally on a Pi. To be more specific: on a Raspberry Pi 2. After trying Jasper and some other projects my personal conclusion was that the small device is not powerful enough for the heavy lifting. This said I just want instant results. And I want to talk from anywhere in the room. I don’t care where the microphone is located. So I started the project SoPaRe to figure out what is possible. My goals were (and still are):
- Real time audio processing
- Must run on small credit card sized, ARM powered computers like Raspberry Pi, Banana Pi and alike
- Pattern/voice recognition for only a few words
- Must work offline without immanent dependencies to cloud APIs
- Able to talk free from anywhere in a room
I must admit that I did not expect much trouble as it’s only data processing. Well, I changed my view and learned a lot. My current result is a first usable system that is able to learn sounds (in my case words) and recognize them even when I not talk directly in the microphone but from 2 meter away and from different angles. But let’s start with some basics. The following image shows the printed result of me saying three words: „computer light off“.
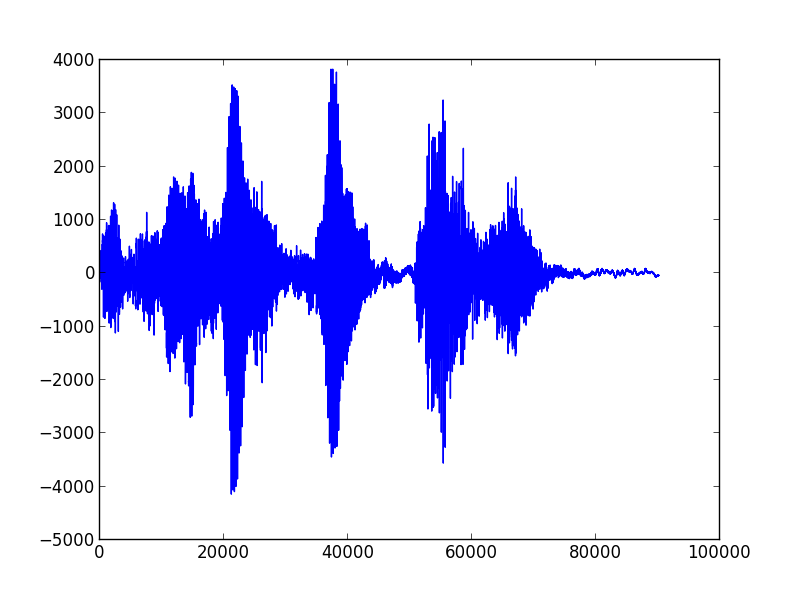
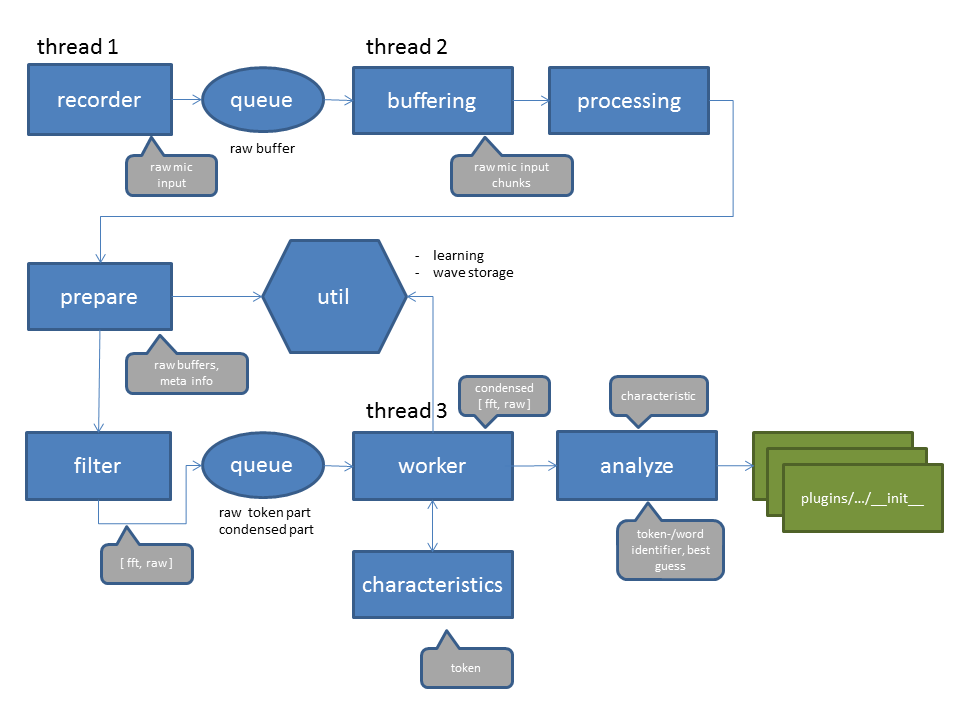
In memory we talk about 80000 values that are generated in roughly 3 seconds. As one of my primary goals was real time processing this number is huge. As the Raspberry PI 2 has 4 cores one of my first decisions was to leverage real threads and process the data on different cores to get a good throughput. Another broad idea was to crunch the data and work with just a small characteristic of the sound. This diagram shows the current project architecture:
First of all we have to „tokenize“ a sound into small parts that can be compared. Like single words from a sentence:
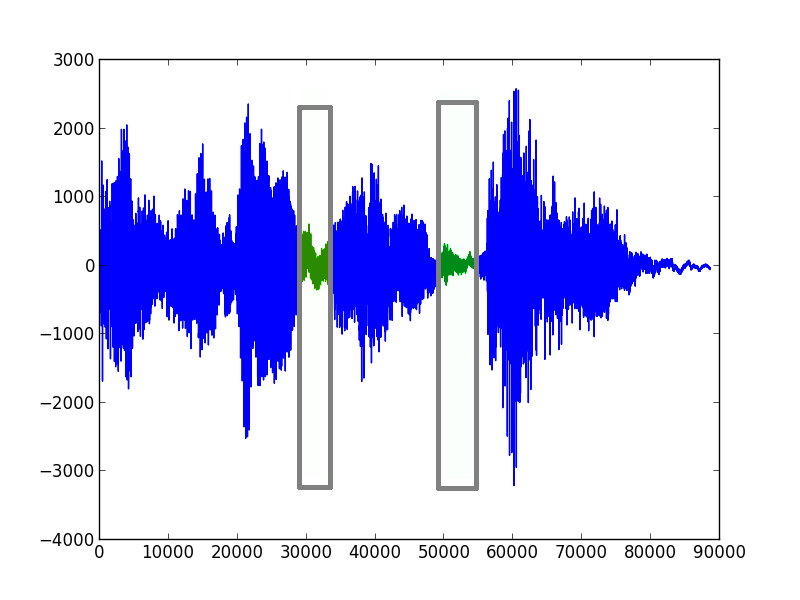
In the current version even a single word is parted into smaller parts like „com-pu-ter“ and for all this parts a characteristic is generated. These characteristics can be stored for further comparison. I tried quite some stuff but I get decent results with a combination of a condensed fast Fourier transformation and rough meta information like length and peaks.
The current version is able to not only match learned words in a sentence but also does this is a real environment. This means standing in a room and the microphone is somewhere located in the corner. Or speaking from quite a distance. On the other hand I still get false positives as the approach is rough. But I’m quite happy with the current state that’s why I talk about it now. The project (SoPaRe) incl. the source code is located on GitHub. Happy to receive your feedback or comments and of course, if you are using SoPaRe, please tell me about it!
My next step is to kick off the beta testing and enhance here and there. Will write again when we have more results after the test phase 🙂