After installing, configuring and training SOPARE, you want naturally do something with the recognized results. I run some installations where SOPARE turns lights on and off, controls a magic mirror and a robotic arm. With my voice. On a Raspberry Pi. Offline and in real time. How does that work? Glad you are asking. This post should give you an overview about SOPARE in terms of the architecture and provide some insights how to write your own custom plugins for further processing.
SOPARE is written in Python and runs very well with Python 2.7 and was tested successfully on several Raspberry Pis running all kind of operating systems. In fact, SOPARE should run on all kind of *UNIX systems if the underlying hardware comes with a multi core CPU. Here you find more information about how to get started. Now let’s make a small walk through. When you start SOPARE with the command
./sopare.py
we can look at this simplified list what’s happening:
Check for arguments from the command line and init parameters
Load the config file
Evaluate the init parameters
Initialize the audio
Read input from microphone
Check if the sound level is above the THRESHOLD
Prepare
Filter
Analyse
Check for matching patterns
Call plugin(s)
Stop everything after the configured timeout is reached
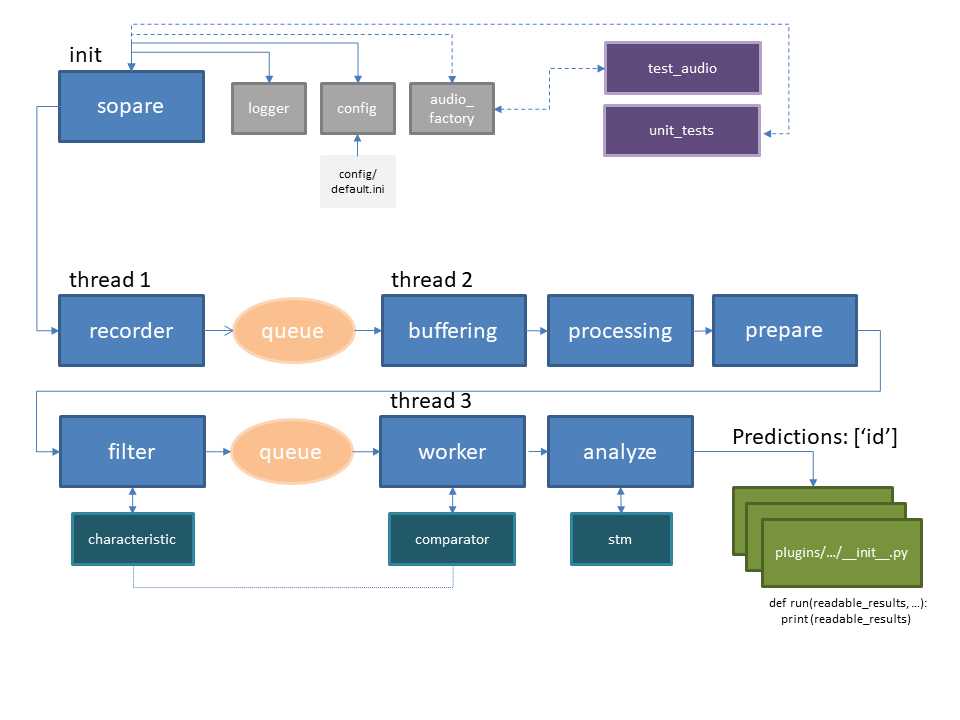
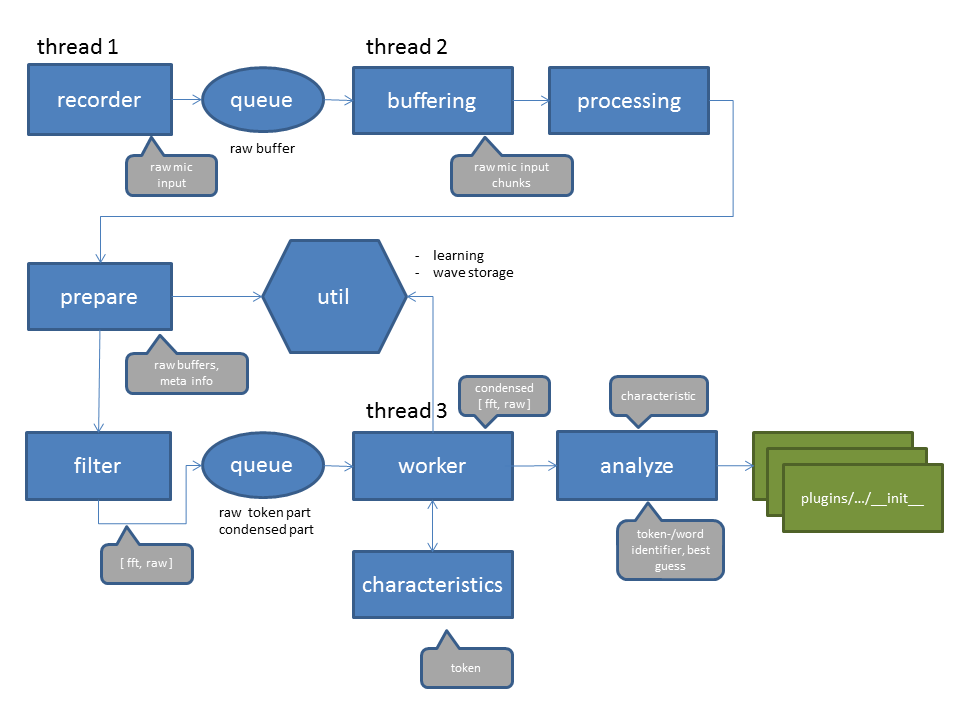
Below is an architecture overview:
Now we can dig a bit deeper and do a more detailed view. The first thread (thread 1) is listening the whole time and records chunks of data. This small chunks of data are compared in terms of sound volume. Whenever one CHUNK volume is above the THRESHOLD the chunks are transformed, filtered and a characteristic is created. This happens in „thread 2“. The chain of characteristics are compared against trained results and the plugins are called in „thread 3“. Each thread runs on a different CPU core. This can be observed when SOPARE is running by starting the command Continue Reading →
After a round of optimization, refactoring, bug fixing and testing it is time for a new blog post. Since fundamentals have changed and due to public requests, we do a step-by-step tutorial. First of all, the good news: SOPARE 1.5 is out and was successful developed, installed and tested on Raspbian Wheezy, Jessie and Stretch. In addition, people mentioned that SOPARE works on Orange Pi and on some Ubuntu versions. Just in case you have no idea what SOPARE is let’s do a quick introduction:
SOPARE stands for SOund PAttern REcognition and is a Python project developed on and for the Raspberry Pi. The goal is to provide offline and real time audio processing for some words that must be trained upfront.
As SOPARE is able to learn sounds from training sessions SOPARE is able to identify the same sound later on even under different circumstances. This means that you can train words in any languages. Or just sounds like doorbells, knocks and whatever you want. Of course, there are limitations. However, SOPARE provides a simple plug-in architecture for further processing. Here are some real life operational areas: SOPARE runs 24/7 and controls smart home things like lights (on/off), a magic mirror (wake up, change views, …) and another installation controls a robotic arm via voice commands. The source code and even more information is available on GitHub.
You want to see SOPARE in action? Here is a 32 second video that shows the potential:
Now let us start with the hardware requirements. You need a computer. Yep, seriously. As SOPARE was developed for and on a Raspberry Pi we go with this one – even if SOPARE runs on other hardware as well. Make sure that the hardware comes with a multi core processor. This means Raspberry Pi 2 or 3. Please note: The Pi zero was not tested and could be too weak even if the „0“ comes with 2 cores. SOPARE does not run on older hardware like Raspberry Pi B or B+ due to the lack of multi-core processors. Of course, you need a power supply and a micro SD card if you go with the Raspberry Pi.
Then you need a microphone. Maybe some USB-mic. The microphone is extremely important and should fit your own requirements. For example: If you want speech recognition across a large distance (more that 1 meter) you may find out that the cheap USB-mic for 5 Euros does not do the trick. But if you plan to speak directly into the microphone the same mic could do the job just perfect. I’m using different microphones for different environments and requirements.
That’s it for the hardware. Now let’s talk about software. SOPARE should run on every Raspbian version that is out there. The latest version is Stretch. All of my Raspberry Pis are running the „lite“ version without a desktop UI. But this is up to you and you can choose whatever you prefer. There is some good information available how to download, install and configure Raspbian. I don’t cover this topic as it would get out of hand.
Now you should have a computer, a mic and the operating system installed and configured. In terms of Raspbian you already got most of the software for the further installation. Only some required libraries must be installed manually with the following commands:
I recommend to create a development directory in your home directory but this is really optional. In case you follow my recommendation execute the following commands:
cd
mkdir dev
cd dev
You are now ready to install SOPARE from GitHub:
git clone https://github.com/bishoph/sopare.git
Voilá. To really be ready and to follow the complete instructions we need two more directories:
cd sopare
mkdir tokens
mkdir samples
You successful installed SOPARE. Congratulations. We can fire up some tests to find out if all requirements are met and if the microphone is configured and used correctly. Start SOPARE and the audio test with the following commands: Continue Reading →
Just a quick head up: SOPARE 1.5 is released and of course this version is the best version that is currently available 😉
SOPARE stands for SOund PAttern REecognition and it is a Python program that provides offline and real time voice recognition on a Raspberry Pi or alike. The source code is available. Read more.
Many things have changed since the last video tutorials were made.
You will notice that the configuration file changed and moved to another location. In addition, the text „start endless recording“ does not appear as promised. If you want the text to appear you can change the log level to „INFO“.
The plan is to create a new, updated tutorial with lots of interesting stuff inside. There is already some feedback available from the former tutorials (e.g. make the console text bigger or better readable, start from scratch video, …) and I’ll do my best to consider that.
However, if you have ideas or special requests please do not hesitate and write a comment to let me know.
Whoa, it’s about time to talk about accuracy and precision in terms of SOPARE. SOPARE is a Python project that listens to microphone input and makes predictions from trained sounds like spoken words. Offline and in real time.
Before we go into the details we make a quick excursion how SOPARE is processing sound. The microphone listens permanent and records every sound in small chunks. As soon as the volume of a sound reaches a specified threshold, SOPARE adds some small chunks and creates a bigger chunk. At this time, SOPARE has an array of data in raw mic input format. The input receives some filtering (HANNING) and the time domain data is transformed into the frequency domain. Now SOPARE removes unused frequencies as specified in the configuration (LOW_FREQ and HIGH_FREQ).
At this stage SOPARE is able to compress the data (MIN_PROGRESSIVE_STEP, MAX_PROGRESSIVE_STEP). Compression is a big factor of precision. Progressive steps mean that a number of frequencies are combined into one value. A progressive step of 100 takes 100 values and creates one (1) combined value. This is a very rough preparation and a good way to create lots of false positives. The opposite would be a step of one (1) which would use each frequency for the characteristic and prediction and represents the max. accuracy – but maybe also the worst true positive recognition.
This is how the process looks like. From the full blown time domain data (40000), to the specified number of frequencies (600) and at the end there is a compressed set of data (24) which is quite clear and used for the predictions.
You need to test around and find some good values for your setup and environment. If you have optimal values, train your sound patterns.
Please note that the values in the section „Stream prep and silence configuration options“ must be used for training and whenever you change them you need to do a new training round. This means remove the trained files via
mv dict/*.raw /backup
or
rm dict/*.raw
and train again!
Now let’s talk about options to enhance precision and accuracy. First of all, you should note that one identifier is always susceptible for false positives. Checking for two or more patterns/words increase the precision big time.
The second option is to make use of the config options to increase the accuracy. Let’s start with the one that identifies a word or pattern:
MARGINAL_VALUE
The marginal value can have a range between 0 and 1. Zero (0) means that everything will be identified as the beginning of a word, 1 means that the trained sample and the current sound must match 100%. Good values lie between between 0.7 and 0.9. Test around how high you can increase the value while still getting real results. For testing purpose keep this value quite low.
MIN_CROSS_SIMILARITY
is the option that is used for comparison. Again, 0 means everything is a match and 1 means that the trained pattern and the current sound must match 100%. For one word scenarios, this value can be quite high, two or more words require normally lower values as the transitions from two patterns are most likely not as single trained words. Good values in my setups are between 0.6 and 0.9. 0.9 for single words, lower values for multiple word recognition.
The following values have a huge impact but I can’t hand out best case values. Instead, they require some manual testing and adjustment:
MIN_LEFT_DISTANCE
MIN_RIGHT_DISTANCE
These values are somehow special. For each word/pattern SOPARE calculates the distance from the trained word and the current sound. A low distance means that the characteristic is similar, high distances means that there is a difference. Left and right means that the frequency ranges are halved and the lower and higher bandwidth is compared respectively. Even if a prediction for the whole word is very close, even a small distance can be essential to filter out false positives. The debug option reveals the most important values:
Again, this requires some fiddling around to find the optimal values that gives true positive and avoid the false ones…start with high values and reduce until you are satisfied. In my smart home light control setup the values are around 0.3 and my false positive rate is near zero although SOPARE is running 24/7 and my house is quite noisy (kids, wife, …).
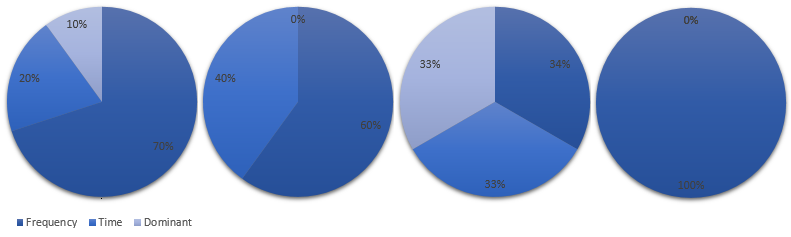
The last config options to consider is the calculation basis for the value „MIN_CROSS_SIMILARITY“. The sum of the three following values should be 1:
„SIMILARITY_NORM“ is the comparison of the FFT similarity.
„SIMILARITY_HEIGHT“ compares against the time domain shape. Good if you want to consider a certain volume.
„SIMILARITY_DOMINANT_FREQUENCY“ is the similarity factor for the dominant frequency (f0).
I recommend to play around with this values and learn the impacts. Based on the environment, sound and the desired outcome there are plenty of possible combinations. Here are some examples:
Puuhhh, this post got longer than expected and the videos have also 25 minutes content. Hope I got everything covered:
Part 1:
Part 2:
Part 3:
Part 4:
That’s it. If you have questions or comments don’t keep back and let me know 😉
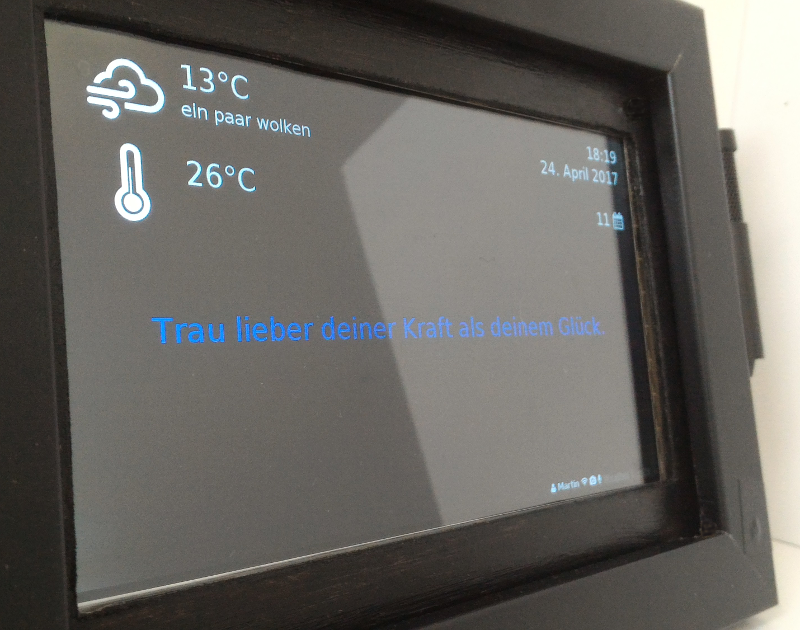
In the last post I did a quick sopare intro and we controlled a robotic arm via voice. Today I want to focus on simple one word commands and how to add custom features to sopare. And because I need something to control I use a smart mirror web interface which is one of my next projects I’m working on. It’s not yet a mirror but the frame, screen, a usb mic and some more parts are already assembled and I think this is a perfect example how to use sopare with one word commands.
The magic mirror prototype that will be controlled via voice
So, let’s start with the requirements. Obviously, you need a Raspberry Pi 2/3. And a microphone. All my sopare systems are using USB microphones. Here is a list that I’m using for different objectives:
Blue Microphones Snowball USB Mic (light control)
Samson Meteor Mic USB Studio (robotic arm control)
Foxnovo Portable USB 2.0 Mic (magic mirror control)
And of course, you need sopare in the latest version. Before we start the training, it’s a good time to check and adjust the mic input. As I’m working most of the time with a headless Pi, „alsamixer“ is my preferred tool. Just make sure that the input is not too high and not too low. I get good results with mic input levels around the 2/3 mark when the mic input level is not yet in the red sector (see the video for a visual reference). Continue Reading →
Yes, I must admit the test phase went longer than initially thought. But good things take time, right. When one develops a speech recognition software or a pattern detection system stuff can go horrible wrong and the learning curve potentiates at some point.
But anyway, what the hell am I talking about? In a nutshell about SoPaRe. Or the SOund PAttern REcognition project. With Sopare and a Raspberry Pi (technically it works on any Linux system with a multi core environment) everybody can voice control stuff. Like lights, robotic arms, general purpose input and output…offline and in real time.
Even without a wake up word. The local dependencies are minimal. Sopare is developed in Python. The code is on GitHub. Cool? Crazy? Spectacular? Absolutely! I made a video to show you whats possible. In the video I control a robotic arm. With my voice. Running Sopare on a Raspberry Pi. In real time. Offline. And it is easy as eating cake. You are pumped? So am I. Here it is:
I may prepare some more tutorials about fine tuning, increase precision and the difference between single and multiple word detection. Let me know what you are using Sopare for, what’s missing or about potential issues.
More than a year ago I’ve written about voice controlled stuff. Enterprise NCC-1701-D like. As you all know: with the rise of cloud APIs this can be accomplished with some work. Downside is that all your talks will be processed in the cloud which means that you may lose your privacy. As I like the Raspberry Pi my goal was to have something running locally on a Pi. To be more specific: on a Raspberry Pi 2. After trying Jasper and some other projects my personal conclusion was that the small device is not powerful enough for the heavy lifting. This said I just want instant results. And I want to talk from anywhere in the room. I don’t care where the microphone is located. So I started the project SoPaRe to figure out what is possible. My goals were (and still are):
Real time audio processing
Must run on small credit card sized, ARM powered computers like Raspberry Pi, Banana Pi and alike
Pattern/voice recognition for only a few words
Must work offline without immanent dependencies to cloud APIs
Able to talk free from anywhere in a room
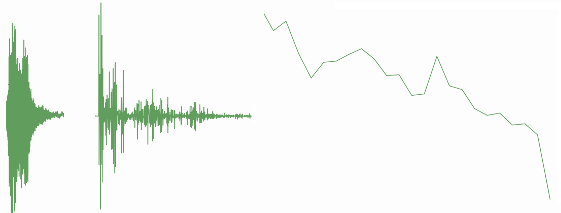
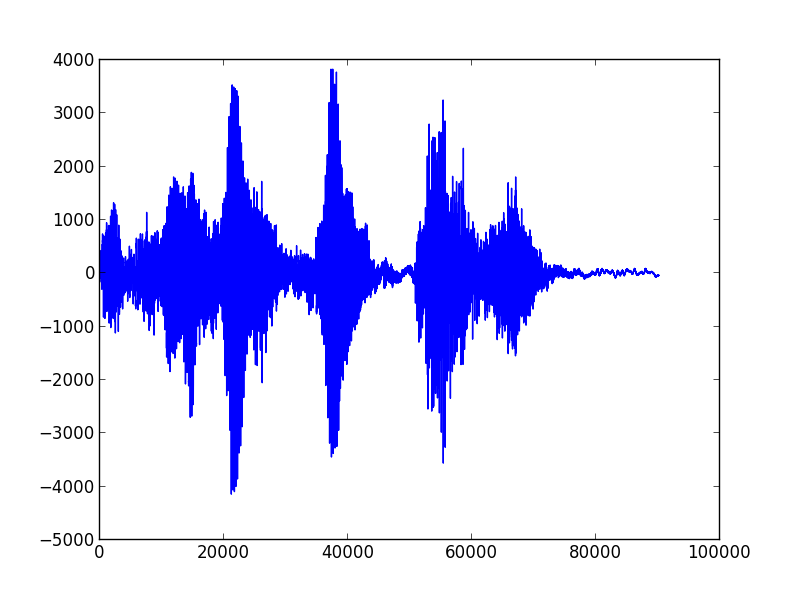
I must admit that I did not expect much trouble as it’s only data processing. Well, I changed my view and learned a lot. My current result is a first usable system that is able to learn sounds (in my case words) and recognize them even when I not talk directly in the microphone but from 2 meter away and from different angles. But let’s start with some basics. The following image shows the printed result of me saying three words: „computer light off“.
In memory we talk about 80000 values that are generated in roughly 3 seconds. As one of my primary goals was real time processing this number is huge. As the Raspberry PI 2 has 4 cores one of my first decisions was to leverage real threads and process the data on different cores to get a good throughput. Another broad idea was to crunch the data and work with just a small characteristic of the sound. This diagram shows the current project architecture:
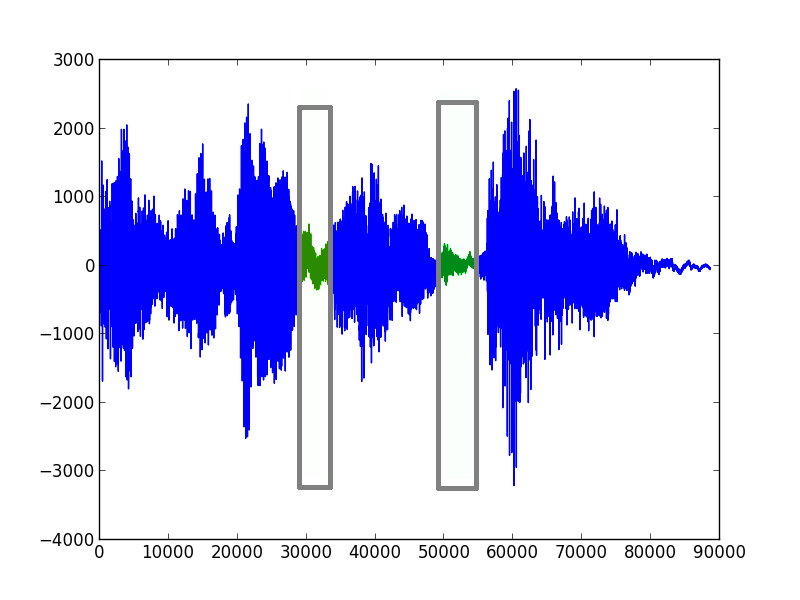
First of all we have to „tokenize“ a sound into small parts that can be compared. Like single words from a sentence:
In the current version even a single word is parted into smaller parts like „com-pu-ter“ and for all this parts a characteristic is generated. These characteristics can be stored for further comparison. I tried quite some stuff but I get decent results with a combination of a condensed fast Fourier transformation and rough meta information like length and peaks.
The current version is able to not only match learned words in a sentence but also does this is a real environment. This means standing in a room and the microphone is somewhere located in the corner. Or speaking from quite a distance. On the other hand I still get false positives as the approach is rough. But I’m quite happy with the current state that’s why I talk about it now. The project (SoPaRe) incl. the source code is located on GitHub. Happy to receive your feedback or comments and of course, if you are using SoPaRe, please tell me about it!
My next step is to kick off the beta testing and enhance here and there. Will write again when we have more results after the test phase 🙂