After installing, configuring and training SOPARE, you want naturally do something with the recognized results. I run some installations where SOPARE turns lights on and off, controls a magic mirror and a robotic arm. With my voice. On a Raspberry Pi. Offline and in real time. How does that work? Glad you are asking. This post should give you an overview about SOPARE in terms of the architecture and provide some insights how to write your own custom plugins for further processing.
SOPARE is written in Python and runs very well with Python 2.7 and was tested successfully on several Raspberry Pis running all kind of operating systems. In fact, SOPARE should run on all kind of *UNIX systems if the underlying hardware comes with a multi core CPU. Here you find more information about how to get started. Now let’s make a small walk through. When you start SOPARE with the command
./sopare.py
we can look at this simplified list what’s happening:
- Check for arguments from the command line and init parameters
- Load the config file
- Evaluate the init parameters
- Initialize the audio
- Read input from microphone
- Check if the sound level is above the THRESHOLD
- Prepare
- Filter
- Analyse
- Check for matching patterns
- Call plugin(s)
- Stop everything after the configured timeout is reached
Below is an architecture overview:
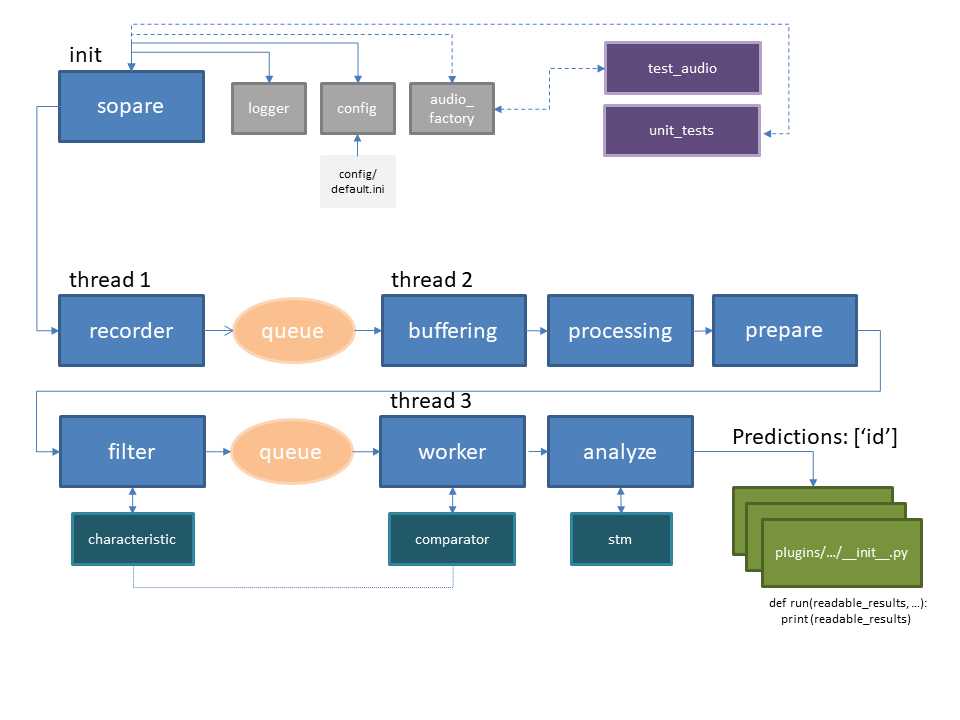
Now we can dig a bit deeper and do a more detailed view. The first thread (thread 1) is listening the whole time and records chunks of data. This small chunks of data are compared in terms of sound volume. Whenever one CHUNK volume is above the THRESHOLD the chunks are transformed, filtered and a characteristic is created. This happens in „thread 2“. The chain of characteristics are compared against trained results and the plugins are called in „thread 3“. Each thread runs on a different CPU core. This can be observed when SOPARE is running by starting the command
top -d 1
and then pressing „1“ to show all CPUs:
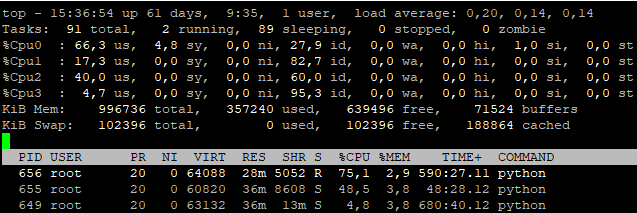
Press „q“ to exit the top output.
As we see in the above picture the SOPARE python processes with the corresponding PID 656, 655 and 649 I want to show two ways to kill SOPARE processes:
First via the „kill“ command and a list of all PIDs:
kill -3 649 655 656
Second via „pkill“ where the processes are killed based on a name:
pkill -3 -f ./sopare.py
I usually send a SIGQUIT as I get the dump to see what the program is doing but you can send any appropriate signal.
Ok. Now that we have touched the architecture and processes, let’s talk about plugins. Plugins are stored in the
plugins
directory. Below you see the plugin structure from my magic mirror pi:

To create a plugin I recommend to copy the print plugin and create a „custom_plugin_directory“ where you replace the name „custom_plugin_directory“ with any meaningful name for your plugin:
cd plugins cp -r print/ custom_plugin_directory
You now have a directory with all necessary files for your custom plugin in the directory „custom_plugin_directory“ or whatever name you have chosen. Let’s modify the plugin and see what’s inside:
cd custom_plugin_directory
The file „__init__.py“ is the one which is called from SOPARE when a sound is regognized. Open it:
nano __init__.py
You see some lines of code and the interesting part is this one:
def run(readable_results, data, rawbuf):
print readable_results
The function „run“ is called and the value „readable_results“ is handed over as an array. This means that each recognized sound is inside this array with the corresponding ID. Let’s assume that you trained a sound with the ID „test“. When the same sound is recognized, then the ID „test“ shows up like this:
[u'test']
If more words are recognized, you get all of them in the array in the same order as they were recognized:
[u'test', u'another_id', u'whatever']
You can now work with the results and write your own conditions. For example, here is the code that just checks for two words:
def run(readable_results, data, rawbuf):
if ('some_word' in readable_results and 'another_word' in readable_results):
print ('Tschakka! Got my two words...now do some awesome stuff')
Here is an example where the results must be in a specific order:
def run(readable_results, data, rawbuf):
if (len(readable_results) == 2 and 'word_1' in readable_results[0] and 'word_2' in readable_results[1]):
print ('Tschakka! Got my two words in the right order...now do some awesome stuff')
With this knowledge you are now hopefully able to read and understand the robotic arm example and write your own plugins. There is one thing I want to mention. All plugins are called sequential. This means you should not execute any complex or long running code without threading!
Ok, I stop for now. I’ll make a video tutorial whenever I have the time. In the meantime don’t hold back and ask questions, make suggestions and give feedback.
Happy coding 🙂
hello,thanks! Can it be recognized under music?
Possible but you may have to reduce the similarity quite a bit which results in false positives.
hi, is it possible to add a sim module?so whnever it recognise a sound it will send me sms..
Anything is possible if you are a developer and with Python it’s normally easy to get stuff done 😉
If you have a GSM/3g modem you can do this and without you can leverage a web service. There are plenty of howtos and documentation available for Python so I encourage you to simply start. You might find these resources helpful:
https://hristoborisov.com/index.php/projects/turning-the-raspberry-pi-into-a-sms-center-using-python/
http://www.ubuntujourneyman.com/2016/04/29/sending-sms-texts-from-a-raspberry-pi-or-ubuntu-box/
Hello, me again who would like to detect specific noises from a closing door. Can we dig here a little deeper in the arcitecture of sopare? 🙂
Jup, we can dig deeper. Just ask some questions so I get the direction…
Hi
I am attempting to run the code in Python 2.7 in the Windows environment. I am getting some errors in the pickling.py routine. In general, should sopare run on a win 7 64 bit environment? Is there anything special I need to change in the configuration?
Thanks
BJ
Never tested SOPARE on Windows as SOPARE is developed on and for the Raspberry Pi. If you resolve the dependencies it might work but I can’t guaranty it.
Hello,
I am trying to understand the logical architecture of sopare.However I can’t come to get how is the training taking place can you help me ?
Sure, I try to help but I don’t have a clue what’s your point is … please explain where you are stuck and how to help 🙂
I need to understand how the training is done ? the algorithm and dependencies to other developped module
Basicly the log info is giving me an idea about the used modules however I still need to understand the algorithm
The architecture overview should give you quite a good overview about the modules and the flow. And a brief description how SOPARE works was described here and here 🙂
good thank you
I have another question, the features characterising each word are: length , frequency and length is that correct ?
Frequencies, shape, length are the most prominent characteristics, but as you can configure quite some stuff you are in control.
Hey,
I am currently working on a speech recognition for the control of a mobile robot. All commands are limited to two consecutive words. After successful training of the vocabulary, I start the endless mode via „./sopare.py -l“. Here, however, my problem arises. Sopare recognizes a few words, but hangs up after those few words (i can’t say which number of words it is…sometimes after 3…sometimes after 24) and stops responding to my audio input. Have you ever experienced this problem? and could you help me with that?
I would be very grateful
Greetings, Julian
Hey. Do you have a custom plugin? Do you experience 100% CPU usage after some time? How many trained words are in the dictionary? One potential reason for the described behavior could be that one process or task takes very long and the work adds up to a point where the system start lagging and therefore SOPARE becomes unresponsive.
Hey, I think this problem could be solved by allocating one processor core per process to guarantee full parallel computing.
Haven’t tried that yet but I’m working m way through cuda computing and I might post about it soon if that works and of corse if you agree
I think that long running code that runs inside a plugin should be started as thread to avoid delay. As SOPARE itself uses the multiprocessing library multiple cores are used already. See the architecture diagram for details:
https://www.bishoph.org/wp-content/uploads/2018/03/sopare_architecture_20180310.png
Hey. I haven´t checked the part with the CPU usage so far as i hadn´t got time last week but i will do it tomorrow. And Yes i do have a custom plugin which is responsible for the movement of the robot. In my dictionary are 7 words – each trained around 5 times. Maybe I should try to start my own code as a thread as you recommended. I will come back here after i tried it. Thank you so far for your advice!
Hey. I just want to inform you that the problem was caused by a mistake in my custom plugin. So there is no problem at all with your speech recognition engine :). But thank you very much for your quick response and your help.
Great to hear and thx for the feedback 🙂
Have fun!
Great work and it is very fun using this tool. I am intermediate with python and I know my commands and operations. It is rare to see educational or tutorial about back-end architecture. Where can I go to learn more about how Python REALLY works? Such as how scripts interact and communicate ETC. I have looked around but not much luck, not sure if I am using wrong words.
Hey, thanks you like it. There are plenty of resources available for Python…you can make a good start here:
https://www.python.org/about/gettingstarted/
https://www.raspberrypi.org/blog/learning-python-with-raspberry-pi/
other than that and just search for a topic you are interested in and start exploring 🙂
can you please explain the method of feature extraction and classification?
I already answered this question for you. If you don’t like the answer you can try a different, more specific answer. BTW: You asked 3 times the same question so far…!?
i had an error when implementing plugins
when i tried to write to __init__.py file the following error appear:
Error writing __init__.py: permission denied
please need your help to fix this problem
If you are working in the git repository directory structure something went wrong big time. Start from scratch and in a new folder structure is my best advice. Other than that: You need permissions to write a file:
https://www.linux.org/threads/file-permissions-chmod.4124/
Hi,
I want to run the infinite loop at boot of the raspberry pi. Any suggestions on how I can do this…
Sure. Create a init.d start/stop script. And because I’m such an awesome guy you can use this one:
https://github.com/bishoph/Misc/blob/master/sopare_service
hi
i have the same problem like julian.when i run ./sopare.py -l after 3 or 4 words that i say, sopare stops responding and doesnt react to voice.im not using any plugin and i just followed the step by step instructions.i have 2 words in my dict and each one about 4 or 5 times trained.im trying to control a robot and add my plugin but now its just sopare itself and the problem occurs.would you please guide me how to solve it?
plus i want to use the speech recognition for long periods.is it possible or is there any limitations or something that needs to be done?
thanks
Any error messages or a process list (like top) to see what happens?
Hi, do you think it’s possible to recognize phonemes than words? Than the API doesn’t need to much resources. I would like to use Sopare for my own home assistant. There I’ve got some servers which will process the nlp afterwards.
Thanks in advance.
BR Daniel
You can try this by adjusting the config. Not sure if it fits your needs but you should give it a try 🙂
Hey, is there a way you can make sequence? So you say for example „Bathroom“, the System processes the command, than asks you for your next command like „lights“, than some processing and after that an other command from you. That would be really helpfull for me. I hope it is clear what i mean.
Thanks for the great documentation.
VG Christopher
Not out of the box but with a custom plugin it’s possible and not too complicated 😉
Have fun!
ALSA lib pcm_dsnoop.c:618:(snd_pcm_dsnoop_open) unable to open slave
ALSA lib confmisc.c:1281:(snd_func_refer) Unable to find definition ‚defaults.bluealsa.device‘
ALSA lib conf.c:4528:(_snd_config_evaluate) function snd_func_refer returned error: No such file or directory
ALSA lib conf.c:4996:(snd_config_expand) Args evaluate error: No such file or directory
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM bluealsa
ALSA lib confmisc.c:1281:(snd_func_refer) Unable to find definition ‚defaults.bluealsa.device‘
ALSA lib conf.c:4528:(_snd_config_evaluate) function snd_func_refer returned error: No such file or directory
ALSA lib conf.c:4996:(snd_config_expand) Args evaluate error: No such file or directory
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM bluealsa
connect(2) call to /tmp/jack-1000/default/jack_0 failed (err=No such file or directory)
attempt to connect to server failed
Yeah, an unrelated snippet of ALSA output without further context. What the heck!
Ok, let’s comment this and assume it has something to do with SOPARE: If you run SOPARE and in case of an error the keyword error appears in the output.
Note to myself: On my TODO list is now an issue to mark ALSA output as ALSA output and separate it completely from SOPARE output as 95& of all problems, questions and stuff is around ALSA output.
Hey bishophdo, how are you? I’m new to Python and I have some doubts. Using Sopare can I get the characteristic string of the word that was spoken and recognized as a trained word? My goal is to find some patterns and differences through this chain of features and to be able to estimate the distance from the sound source to the microphone. I thought about maybe using THRESHOLD of words, doing a calibration and determining an estimated distance value for each THRESHOLD. Thank you.
You can train sounds with SOPARE and SOPARE may gets you predictions and results based on your training. Distance estimation is beyond SOPAREs scope. You should look at a different project or approach.
Yes I wanted to work with the help of SOPARE just to make the recognition of the sound, regarding the distance estimation I will implement something still, so I would like to know if I can access the chain of characteristics that SOPARE generates to make the comparison with the sound trained. Do you know if I can save this file? Because then I see if I can work on these data.
Hey bishoph, how are you? I was reading some topics in git and found the –wave function of SOPARE, this function creates wave files only of the words trained and saved in the dictionary or the words that are recognized while the program is being executed are also saved? Could you help me with this question?
Hey. SOPARE creates „.wav“ files for the recognized words and their parts as SOPARE processes them. You find the files in the folder „tokens/“.
Hello,
Let’s suppose I train SOPARE to recognise the words „events“, „today“ and „tomorrow“, but I am not happy with the training data for the word „events“ as there was a lot of background noise when I trained it.
Is there any way to only delete training data for the word „events“ without deleting the training data for all the other words?
Thank you
Yes. You can delete trained data for one id and keep the rest of the training data.
Delete trained data for the id events:
After that re-create the dict:
Deleting single training data is a bit more complicated as you have to delete the raw data files and re-create the dict again. If somebody needs to know the how to I’ll explain it.
Hello Martin,
I have a problem with characteristic.py. Could you support me, please?
I see you calculate Discrete Fourier Transform (fft) for feature extraction but I dont know what algorithm it is. Is it Mel frequency cepstral coefficients (MFCC) or Perceptual linear prediction (PLP) or something else?
Thank you.
Hi. I had no idea what PLP and MFCC is so I had to search for it. Reading through it, SOPARE uses some of the procedures of both PLP and MFCC like power spectrum calculation, filtering, equalizing, smoothing and if I understand it correctly also some kind of lifting. But as I haven’t looked much into other speech processing software/concepts while writing SOPARE these techniques seems to be necessary to get the work done. If you search for technical implementation of well known and named procedures SOPARE is the wrong place to search. Hope that helps.
Hi Martin,
First; This is a real cool project (and helpful documentation)! Just stumbled upon it as I was looking into how to use an rpi3 to recognize different types of noises.
The (training) use-case I have is that I have mp3 recordings of the various noises I want to monitor, using audacity I can extract a number of occurrences of each noise and export them into e.g. raw format (that from what I understand can be used as input to sopare). Though I do no see any entry in dict.json (or any other file created)
What I do is this:
$ python sopare.py -c ~/noise1_1.raw -t hund1 -v
sopare 1.5.0
recreating dictionary from raw input files…
$ python sopare.py -o
sopare 1.5.0
current entries in dictionary:
Is there a specific encoding expected for the .raw files (tested so far with VOX_ADPCM and signed 32-bit PCM)?
Best regards
Hi. The „raw“ format is indeed a bit misleading as it has nothing to do with sound encoding raw format(s). The raw in terms of SOPARE stands for raw data. To create this format sound must run through the SOPARE training method…sorry. There is already a feature request for using mp3 as training method on GitHub…
HI Martin,
Thanks for the clarification! I made a work-around by making a virtual microphone and then played the sound files through that. Made scripted tested tests of different sopare config settings a bit easier (still learning about that though) 🙂
For anyone interested until native support for sound file exists, this is my bash script:
#!/bin/bash
CFILE=“/home/my_user/.config/pulse/client.conf“
MICFILE=“/tmp/.virtmic“
print_usage()
{
cat >> usage.txt <<USAGE
This script will either:
1) Create a virtual microphone for PulseAudio to use and set it as the default device.
2) If configured to 1), revert back
Usage:
sound_redirect.sh
-h Print this help
USAGE
cat usage.txt
rm usage.txt
}
set_up_virtual()
{
# Create virtual microphone that reads audio data from a named pipe
pactl load-module module-pipe-source source_name=virtmic \
file=$MICFILE format=s16le rate=16000 channels=1 > /dev/null
# Set the virtual microphone as the default device
pactl set-default-source virtmic
# Create a file that will set the default source device to virtmic for all
# PulseAudio client applications.
echo „default-source = virtmic“ > $CFILE
# Now an audio file can be written to $MICFILE
# A write will block until the named pipe is read.
}
revert_back()
{
# Uninstall the virtual microphone, remove it as default source
pactl unload-module module-pipe-source
rm $CFILE
}
parse_input()
{
while getopts „:h“ arg; do
case $arg in
h)
print_usage
exit 0
;;
esac
done
}
sound_redirect_main()
{
if [ ! -f $CFILE ]; then
printf „Setting up system for SOPARE training… “
set_up_virtual
printf „Done\n\n“
printf „To write audio file to virtual microphone, do e.g.:\n“
printf „ffmpeg -re -i input. -f s16le -ar 16000 -ac 1 pipe:1 > $MICFILE\n“
else
printf „Reverting system back from SOPARE training… “
revert_back
printf „Done\n“
fi
exit 0
}
sound_redirect_main $@
Hello
I have a question:
Does SOPARE run on a raspberry pi zero? Or is there a problem because of the multithreading?
Kind regards
Yes, it runs on the zero, but you should know what you are doing and it could lag. I can’t really recommend it. Use it for fun and giggles and it should do the job even if – depending on lots of stuff – you could potentially loose the real time aspect and this would be kind of normal and no bug 😉
Hi bishoph
First of all, thanks a lot for your work! I was very happy to find sopare, as there aren’t many useful programs for offline speech recognition beside yours.
I was wondering if it’s possible to stop the recording after one word is detected. Until now I’ve used the endless mode via „./sopare.py -l“ but is there another option?
Thanks a lot & best regards
Hey. Glad that you like my work!
If you want SOPARE to stop after each detection you can simply start SOPARE without the loop option „-l“. You can also stop SOPARE programmatically in your custom plugin…
Have fun!
hi
how can i change the mic sourse of sopare?
SOPARE is using ALSA for mic input and therefore everything mic related is done via ALSA configuration…
hi again
can we install sopare on windows 10 ??
Nope.
Hi Bishoph,
It has been amazing to find SOPARE, there aren’t many useful programs for offline speech recognition. I successfully installed it on Rspi 3b+. It is able to recognize my sounds well. I am using Raspbian Buster with Desktop (GUI). I am not good at programming, but am learning Python over next few days.
I came across your Python script the generic start up script and saw your YouTube video on Robot arm control. Being that SOPARE is a clean and responsive program, it is impressive that it can control things with such little control.
You mentioned on a different reply, the following:
„Now you may want to ask: How can I control stuff with sopare? Where does my code goes? Good questions. Sopare comes with a simple plugin interface. Just take a look into the directory „./plugins“. You see the standard plugin „print/__init__.py“. This plugin only contains two (2) lines of code that are relevant in terms of coding:
def run(readable_results, data, rawbuf):
print readable_results
The interesting part for the basic usage is the list value „readable_results“. In my case the value contains something like
[u’main‘]
If you simply copy the print plugin you can add your own code and control stuff.
To me and possibly other newbies in programming, it would be helpful if you can elaborate more on this concept. I am trying to control my Rspi GUI and programs installed by speech recognition like basic things to open and respond to voice. For example – have it to open chromium browser, or file manager, or terminal, or libreoffice writer, raspi-config, e-mail etc. What would be a code for each of these in Python? I have Python 3.7 on my machine.
Would my voice command be like 2-3 words – open terminal, open internet browser, open libreoffice writer? and what would be the execute scripts?
Hi, glad you find SOPAPE helpful. And yes, you can execute scripts with Python. I recommend to get some knowledge and basic development background using Python. Then, everything becomes possible. Here is a link how to execute scripts and other programs in Python:
https://stackoverflow.com/questions/89228/how-to-call-an-external-command
Also, there is a ton of stuff to get started:
https://wiki.python.org/moin/BeginnersGuide/Programmers
Have fun!
Also you said:
Can be used in combination with any available cloud API or service like Alexa: https://developer.amazon.com/public/solutions/alexa/alexa-voice-service
Google: https://cloud.google.com/speech/
(and many more)
I have Amazon Alexa installed and running on my machine. How can I integrate SOPARE with Alexa? ie run both integrated scripts upon boot and respond continuously thereafter
I control stuff like lights with Alexa and with SOPARE. As every environment is different and you may have other requirements/goals all I can say is that there are plenty of combinations and possibilities…
Sir..
I want to send a mail and also trigger a Arduino using voice.. What can I do.. Can u give me codes or suggestions.
All this I want in raspberry pi with ur sopare running
Hmm, let’s see – I would use the plugin I already provided, enhance it to send a mail and then trigger the Arduino.
Have fun 🙂
Hello Martin
Fantastic Project! I am quite impressed of how easy the training works. Although I am struggeling a bit in setting up a script that uses the plugin. Might you provide a simple (full-working) example-script which maybe prints something on recognition of a specific word?
Thank you very much. Keep up your fantastic work.
Hi, thanks and glad you like it. Here is my robotic arm example:
https://github.com/bishoph/Misc/blob/master/robotic_arm_control.py
Have fun 🙂
hi bishoph,
Can you explain me the working principle of the SOPARE ?
How it actually works and matches the wave patterns ?
thank you
Hi Nahian, I explained the working principle, how SOPARE works and the architecture in this posts:
Smart home and voice recognition
Sopare precision and accuracy
SOPARE architecture and plugins
Hi Bishoph,
Great tool. I am having issues using this on python version 3.9.2. I keep getting error:
ModuleNotFoundError: No module named ‚ConfigParser‘.
I am relatively new to python but i found where someone said that I ‚ConfigParse‘ is not supported in python 3, but I could change to ‚configparse‘ I did this and I kept getting multiple errors on other missing modules.
Can you please help with guiding me through a solution, I am hoping to use this tool with my PhD research. It seems like a good fit for what I need. Thank you in advance! 🙂
Did you checkout the testing branch? Currently only the testing branch supports Python 3:
https://github.com/bishoph/sopare/tree/testing
Have fun!