Whoa, it’s about time to talk about accuracy and precision in terms of SOPARE. SOPARE is a Python project that listens to microphone input and makes predictions from trained sounds like spoken words. Offline and in real time.
Before we go into the details we make a quick excursion how SOPARE is processing sound. The microphone listens permanent and records every sound in small chunks. As soon as the volume of a sound reaches a specified threshold, SOPARE adds some small chunks and creates a bigger chunk. At this time, SOPARE has an array of data in raw mic input format. The input receives some filtering (HANNING) and the time domain data is transformed into the frequency domain. Now SOPARE removes unused frequencies as specified in the configuration (LOW_FREQ and HIGH_FREQ).
At this stage SOPARE is able to compress the data (MIN_PROGRESSIVE_STEP, MAX_PROGRESSIVE_STEP). Compression is a big factor of precision. Progressive steps mean that a number of frequencies are combined into one value. A progressive step of 100 takes 100 values and creates one (1) combined value. This is a very rough preparation and a good way to create lots of false positives. The opposite would be a step of one (1) which would use each frequency for the characteristic and prediction and represents the max. accuracy – but maybe also the worst true positive recognition.
This is how the process looks like. From the full blown time domain data (40000), to the specified number of frequencies (600) and at the end there is a compressed set of data (24) which is quite clear and used for the predictions.
You need to test around and find some good values for your setup and environment. If you have optimal values, train your sound patterns.
Please note that the values in the section „Stream prep and silence configuration options“ must be used for training and whenever you change them you need to do a new training round. This means remove the trained files via
mv dict/*.raw /backup
or
rm dict/*.raw
and train again!
Now let’s talk about options to enhance precision and accuracy. First of all, you should note that one identifier is always susceptible for false positives. Checking for two or more patterns/words increase the precision big time.
The second option is to make use of the config options to increase the accuracy. Let’s start with the one that identifies a word or pattern:
MARGINAL_VALUE
The marginal value can have a range between 0 and 1. Zero (0) means that everything will be identified as the beginning of a word, 1 means that the trained sample and the current sound must match 100%. Good values lie between between 0.7 and 0.9. Test around how high you can increase the value while still getting real results. For testing purpose keep this value quite low.
MIN_CROSS_SIMILARITY
is the option that is used for comparison. Again, 0 means everything is a match and 1 means that the trained pattern and the current sound must match 100%. For one word scenarios, this value can be quite high, two or more words require normally lower values as the transitions from two patterns are most likely not as single trained words. Good values in my setups are between 0.6 and 0.9. 0.9 for single words, lower values for multiple word recognition.
The following values have a huge impact but I can’t hand out best case values. Instead, they require some manual testing and adjustment:
MIN_LEFT_DISTANCE MIN_RIGHT_DISTANCE
These values are somehow special. For each word/pattern SOPARE calculates the distance from the trained word and the current sound. A low distance means that the characteristic is similar, high distances means that there is a difference. Left and right means that the frequency ranges are halved and the lower and higher bandwidth is compared respectively. Even if a prediction for the whole word is very close, even a small distance can be essential to filter out false positives. The debug option reveals the most important values:
sorted_best_match: [[MIN_CROSS_SIMILARITY, MIN_LEFT_DISTANCE, MIN_RIGHT_DISTANCE, START_POS, LENGTH, u'PREDICTION'], [MIN_CROSS_SIMILARITY, MIN_LEFT_DISTANCE, MIN_RIGHT_DISTANCE, START_POS, LENGTH, u'PREDICTION']]
Again, this requires some fiddling around to find the optimal values that gives true positive and avoid the false ones…start with high values and reduce until you are satisfied. In my smart home light control setup the values are around 0.3 and my false positive rate is near zero although SOPARE is running 24/7 and my house is quite noisy (kids, wife, …).
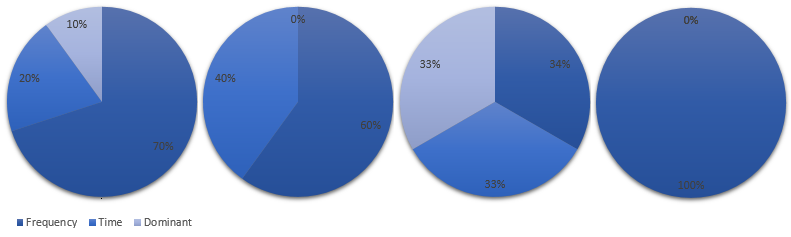
The last config options to consider is the calculation basis for the value „MIN_CROSS_SIMILARITY“. The sum of the three following values should be 1:
SIMILARITY_NORM SIMILARITY_HEIGHT SIMILARITY_DOMINANT_FREQUENCY
„SIMILARITY_NORM“ is the comparison of the FFT similarity.
„SIMILARITY_HEIGHT“ compares against the time domain shape. Good if you want to consider a certain volume.
„SIMILARITY_DOMINANT_FREQUENCY“ is the similarity factor for the dominant frequency (f0).
I recommend to play around with this values and learn the impacts. Based on the environment, sound and the desired outcome there are plenty of possible combinations. Here are some examples:
Puuhhh, this post got longer than expected and the videos have also 25 minutes content. Hope I got everything covered:
Part 1:
Part 2:
Part 3:
Part 4:
That’s it. If you have questions or comments don’t keep back and let me know 😉
As always, have fun and happy voice controlling 😉
Hi,
I’m trying to adjust SOPARE for detecting door knock pattern – if someone knocked 2x or 3x times.
Scenario is like this:
– Train SOPARE with two patterns (sopare.py -t 2xknock & -t 3xknock)
– compile and then loop
– whenever THRESHOLD value is detected listen for pattern until silent for max1sec
– compare recorded audio with 2xknock and 3xknock patterns
– printout if something is detected.
This would be very smart detection of knocks. There are many tutorials for detecting knocks on RPI, but they all look only for threshold level and detect knock on every noise that is loud enough.
It all sounds good in theory, but I’m still having problems to get it work. I thought it would maybe help someone if I describe my findings.
Problem 1
———-
1. I train Sopart with „-t 3xknock“ (where I knock 3 times) & then compile it
2. When I go to loop mode 3xknock is detected even if i knock only once
I guess solution would be to set correct timing – so that while training it would actually capture all three knocks and then also listen to all three.
Any suggestion how to set training time so that it will capture all three knocks?
Any suggestion how to listen for 3 knocks in loop mode?
Pattern with 3 knocks is ~1sec long. This well below MAX_TIME = 3.5 defined in config.
Problem 2
———-
I recorded wav of knocks on rpi and then open it on Adobe Audition CC.
I was experimenting with equaliser to filter out other noises.
I found out that if I remove frequencies from 0-500Hz & 2kHz all noises are removed and what is left are pretty much only knocks.
When I try to apply this filter to Sopart by setting:
LOW_FREQ = 500
HIGH_FREQ = 2000
I get very strange error on loop after first THRESHOLD is detected:
—
Process buffering queue:
Traceback (most recent call last):
File „/usr/lib/python2.7/multiprocessing/process.py“, line 258, in _bootstrap
self.run()
File „/home/pi/sopare/sopare/buffering.py“, line 42, in run
self.proc.check_silence(buf)
File „/home/pi/sopare/sopare/processing.py“, line 82, in check_silence
self.stop(„stop append mode because of silence“)
File „/home/pi/sopare/sopare/processing.py“, line 53, in stop
self.prepare.force_tokenizer()
File „/home/pi/sopare/sopare/prepare.py“, line 93, in force_tokenizer
self.tokenize([ { ‚token‘: ’start analysis‘, ’silence‘: self.silence, ‚pos‘: self.counter, ‚adapting‘: 0, ‚volume‘: 0, ‚peaks‘: self.peaks } ])
File „/home/pi/sopare/sopare/prepare.py“, line 52, in tokenize
self.filter.filter(self.buffer, meta)
File „/home/pi/sopare/sopare/filter.py“, line 91, in filter
nam = numpy.amax(nfft)
File „/usr/lib/python2.7/dist-packages/numpy/core/fromnumeric.py“, line 2130, in amax
out=out, keepdims=keepdims)
File „/usr/lib/python2.7/dist-packages/numpy/core/_methods.py“, line 17, in _amax
out=out, keepdims=keepdims)
ValueError: zero-size array to reduction operation maximum which has no identity
—
Sample without filter:
https://www.dropbox.com/s/v5q7j4p7eui0x4q/knock_pattern.wav?dl=1
Sample with filter applied :
https://www.dropbox.com/s/4f3e56dc4kqdp77/knock_pattern_HI-LOW_FILTER.wav?dl=1
Equaliser settings used for filter:
https://www.dropbox.com/s/22e010dazob9e9h/Equilizer_for_filter.png?dl=1
What is causing this?
How to avoid it?
It only happens if I change LOW_FREQ and HIGH_FREQ …
Problem 3
————
If I use -l -~ to save detected patterns I get many very strange sounding wav-s. They sound very high pitch and are only few ms long. There is also no wav with complete 3x knock pattern. Actually I can not recognise even a simple knock.
Sample: https://www.dropbox.com/s/e7877lnakc9gekf/filtered_results0.wav?dl=1
While doing test recording for analysis in Adobe Audition I did it with:
arecord -D plughw:0,0 -f cd test2.wav
Why Am I getting high disturbed wav? Is there anything wrong with sound card setting? I’m using USB sound card.
Thank you for great work,
Gregor
Hi Gregor.
Let`s try to get some ground on your issues. First, do the training with verbose mode enabled. This helps you see if something triggers the training before the first knock. It could be the case that the „THRESHOLD“ is so low that training starts before the real event occurs. In addition, play with the „MAX_SILENCE_AFTER_START“ time. If some sound triggers the training before the knock and MAX_SILENCE_AFTER_START is very low, then you may just get some noise instead of the real thing. Training with verbose mode enabled helps you to avoid such false training sets. Make sure to delete false training files (I mean the corresponding raw files in the dict/ directory before compiling the dict).
Problem 2 could be a bug or the result of empty frequencies/no values. In combination with problem 3, try to increase the „CHUNKS“ in the config file to higher values like 4096 or even 8192. The frequency analysis is called whenever the size of the „CHUNKS“ value is reached. Seems that in your case the input is too small and/or filtered too much as you just get garbage in the single tokens SOPARE is using for the analysis. If the error still occurs I suggest that you open an issue on GitHub.
Hope that helped. Have fun!
I trained 3 knocks, no special config options or filtering. The issue for SOPARE to recognize the trained 3 knocks was that the timing between the 3 knocks seems to be always different and therefor a true recognition is difficult. You need very low similarity values to get true results. What I did next: I trained 1 knock several times. The 1 knock was easily recognized and knocking 2 times resulted in this:
[u’knock‘]
[]
[u’knock‘]
You could leverage the short term memory option (set „STM_RETENTION“ to something like 1 seconds) to get a result like this for easier further processing:
[u’knock‘, u’knock‘]
Of course very fast knocking missed some knocks in between but nonetheless the knocking was recognized at least once. Hope this gives you some ideas 🙂
Hi,
Thank you for very fast answer.
It turned out that my mic was a bit of crap. I replaced it with piezo contact mic and it works much better at detecting knocks. I also did tweak config.py based on your youtube tutorial.
Increasing CHUNKS works – error no longer appears. It how ever works better with out limiting frequencies now that I have another mic.
Knocks are now detected consistently. Which is perfect.
There are how ever two additional questions:
1. If I make many multiple trainings on the same word I get many „stream read error [Errno Input overflowed] -9981“ messages while in loop. When this errors appears detection is not that good.
2. How to lower time to detect repeatable knocks – if i knock two times very fast than knocks are not detected (I’m using MAX_SILENCE_AFTER_START = 0.4).
Regards,
G
It’s a pleasure to answer your questions. Great to hear that it works better now.
The issue „stream read error [Errno Input overflowed] -9981“ is something I also see quite often and it’s an issue that is Pi related. But the issue also appears on other systems. Maybe due to the concurrent use of network interface and USB port we Rasbperry Pi users face this issue more often. The issue means that the input has more data but the data can’t be processed fast enough. This has an impact on precision as one or more chunks of data are missing either in training or in the prediction phase. But the impact is negligible in my opinion as the default 512 bytes are just a fraction of a second. Maybe someday the RasPi USB port gets more bandwidth and throughput…
The second issue is something I can’t answer in general. One knock takes maybe around 0.4 to 0.7 seconds which means your used value is already very small. Very fast knocks most likely have different sound characteristics and length – maybe a valid solution is to train the common one knock and in addition train the outliers to increase the overall true positives. The only value that affects the time is this one:
LONG_SILENCE
Other than that: try and test around several config options that works best for you, your use cases and the environment you are in.
Have fun 🙂
Hi bishoph,
could you be please so kind and give some more examples? E.g how to train sopare with more words than one. Like „Licht an/Licht aus“ Also I did not find out yet how to make sopare executing commands on the shell. I’m not really a coder. I’m fine with bash scripting but thats it. So please, please write a good docu with a lot of examples. Don’t want to see this project going down like Jasper or other great opensource projects. Since Jasper is not useable. I spent like 20 hours of my freetime for exactly nothing. This is kinda frustrating, since as you might know we all don’t have that much freetime to spent in such things.
So the more examples you can give how to control things (for me in this case: execute scripts/binaries within the bash for controlling my electric sockets(433MHz) the more likely is it that people can easily use your awesome project. Also the benefit would be, the more examples exist, the easier is it to understand the syntax for adapting them for own future projects with sopare. It’s very unlikely that all people who want to use this have the will to learn python from scratch. I am really a friend of RTFM, but for example the documentation of Jasper is that bad, that you have to spent hours to find solutions in different forums, help pages and so on.
Kind Regards
D3M
P.S I like it that you do videos as well. But actually I’m using a full HD TV. The text is so small in the videos that I have to go very near to the screen that I can see something. And even then its very tiny.
Yes, I’ll do more examples and HOWTOs in the future. But as this takes lots of time here is something you can do right now:
1) Two or more commands
This is relatively easy. Just train two commands with the train option you already know:
./sopare.py -t licht
./sopare-py -t an
./sopare-py -t aus
Train each command at least 3 times.
After that, create the dict with
./sopare.py -c
The next step is to find the right config for your commands and your trained words. Just follow the examples and HOWTOs from this blog post. Make sure that the overall time in the config (MAX_SILENCE_AFTER_START and MAX_TIME) suites your commands. Also, the parameter LONG_SILENCE is something you find maybe useful as this value finds the emptiness between the commands words (example: licht LONG_SILENCE an). It helps at the beginning to make an artificial pause (not to long!) between the commands. Just test around a bit.
2) Plugins and execution of bash scripts in Python
There is no way to enhance/customize SOPARE without some Python code. But here comes a very simple plugin that should give you an idea how easy it is. Just place it in the plugin directory (the structure looks like this: „plugins/light_on_off_example/__init__.py“
And here comes the code for the plugin:
#!/usr/bin/env python # -*- coding: utf-8 -*- import subprocess def run(readable_results, data, rawbuf): if (len(readable_results) == 2 and 'licht' in readable_results and readable_results[0] == 'licht' and ('aus' in readable_results or 'an' in readable_results)): # execute bash script: https://stackoverflow.com/questions/89228/calling-an-external-command-in-python # You can even execute the command and provide the arguments readable_results[0] and readable_results[1] # See the link below for details: # https://stackoverflow.com/questions/19325761/python-executing-shell-script-with-argumentsvariable-but-argument-is-not-rea subprocess.call(['/path/to/script', readable_results[0], readable_results[1]])Please note that I’ve not tested the above code and not checked if this really runs as I just want to give you a broad idea how to write a custom plugin.
Thanks a lot! 🙂 I tested the whole night. I also installed raspbian several times and ended up with jessie. Stretch made issues. For example I was able to train, but the not to start with the -l option. It did not recognize any voice command at all after training. For what ever reason.
Can you recommend a good mic? I saw you’re using the snowball for the lights. Do you think something like Matrix (https://creator.matrix.one/) will work as well? Or (http://www.seeedstudio.com/blog/2017/06/21/time-limited-bundle-sales-respeaker-core-respeaker-mic-array-pro-case-for-only-128/)
Plan is to put it behind my couch or somewhere else. Not sure if the snowball is capable for this. Actually Im using an old mic of a headset plugged in the usb audio card.
Since I had also some troubles with using two commands „licht an“ or „licht aus“. within the console sopare shown me only „licht“ and then „an“ or „aus“… Guess I need to play with the values. I just adjusted the script you provided me a bit to do some useless ping.
Maybe someone whos reading this want to test. in terminal do:
cd ~ && echo -e ‚#!/bin/bash\nping -c 1 heise.de‘ > ping.sh && chmod +x ping.sh
plugin:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import subprocess
def run(readable_results, data, rawbuf):
if (len(readable_results) == 1 and ‚licht‘ in readable_results):
subprocess.call([‚/home/pi/ping.sh‘])
For sure you can start any other script. This was just for testing.
Cheers
You are welcome 🙂
As I’m using two Snowball mics I can really recommend them for smart home/home automation controlling. Both mics are working 24/7 in large noisy rooms while speaking from different angles and distances. Noisy rooms because I also track my false positive rate which is so to speak not existing for two and three word activation.
In terms of the Matrix mic: This should work in theory very well as Amazon Alexa/Echo is using something similar for their products and services. Reading their docs, it seems that you can get either one combined channel with all the echos and different sounds or all eight channels with the different sound captures. If this is true then there is the need to do some additional filtering/processing before one can use it with SOPARE.
If SOPARE recognizes the commands in serial than you can increase the short term memory value: STM_RETENTION
By increasing and using the short term memory you get the commands together in your plugin if they fit into the STM_RETENTION window.
Happy voice controlling and have fun 🙂
Hi bishoph,
I’m making progress with this neat tool. I also bought a snowball mic. This is pretty awesome.
Btw. you stated out in another comment when we want to train, the training word should start after „start endless recording“ is shown. I don’t see that at all. What I see is:
——————————————————————————————————————————
./sopare.py -t licht
sopare 1.4.0
ALSA lib pcm_dmix.c:1022:(snd_pcm_dmix_open) unable to open slave
ALSA lib pcm.c:2239:(snd_pcm_open_noupdate) Unknown PCM cards.pcm.rear
ALSA lib pcm.c:2239:(snd_pcm_open_noupdate) Unknown PCM cards.pcm.center_lfe
ALSA lib pcm.c:2239:(snd_pcm_open_noupdate) Unknown PCM cards.pcm.side
ALSA lib pcm.c:2239:(snd_pcm_open_noupdate) Unknown PCM cards.pcm.hdmi
ALSA lib pcm.c:2239:(snd_pcm_open_noupdate) Unknown PCM cards.pcm.hdmi
ALSA lib pcm.c:2239:(snd_pcm_open_noupdate) Unknown PCM cards.pcm.modem
ALSA lib pcm.c:2239:(snd_pcm_open_noupdate) Unknown PCM cards.pcm.modem
ALSA lib pcm.c:2239:(snd_pcm_open_noupdate) Unknown PCM cards.pcm.phoneline
ALSA lib pcm.c:2239:(snd_pcm_open_noupdate) Unknown PCM cards.pcm.phoneline
ALSA lib pcm_dmix.c:1022:(snd_pcm_dmix_open) unable to open slave
ALSA lib pcm_dmix.c:1022:(snd_pcm_dmix_open) unable to open slave
Cannot connect to server socket err = No such file or directory
Cannot connect to server request channel
jack server is not running or cannot be started
——————————————————————————————————————————
So in my env I start directly training the words when I see the „jack server is not running…“
What happens when I do not start directly after I can see this text? Will sopare wait until it gets input of the mic, or will be the silence then used as well?
By the way. Since I made some progress here. I would like to share my results for the people who want to try basic stuff like me with the lights on/of.
Needed things
1. electric socket e.g Brennenstuhl RCS 1000 N Comfort
2. 433MHz receiver/transceiver e.g https://www.amazon.de/Aukru-Superregeneration-433M-receiver-module/dp/B00R2U8OEU/ref=sr_1_2?ie=UTF8&qid=1510664014&sr=8-2&keywords=433+mhz+sender
3. running sopare with trained words
4. git://github.com/xkonni/raspberry-remote.git
5. scripts & plugin (for sopare)
# You might want to put the script in /usr/local/bin/ as you can put in the compiled send binary as well
# Don’t forget to make the script executable chmod +x
# Change the code of your e-socket and use it in the script
if [ $1 == „an“ ]
then
send 1
exit 0
elif [ $1 == „aus“ ]
then
send 0
exit 0
else
exit 0
fi
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import subprocess
def run(readable_results, data, rawbuf):
if (len(readable_results) == 2 and ‚licht‘ in readable_results and readable_results[0] == ‚licht‘ and (‚aus‘ in readable_results[1] or ‚an‘ in readable_results[1])):
subprocess.call([‚couchlight‘, readable_results[1]])
Note: I will continue on this. Like that it’s possible to talk more human like to the sopare instance.
bishoph do you have any recommendations where to finetune the settings? I already checked your videos, but like said the text of the terminal is that tiny that its hard to follow. 🙂 What I want to do is like that you can say a complete sentence, and sopare will use trigger words of the sentence.
Examples:
1. mach/schalte das
2. du bist ein böser Computer, nun mach das
2. fahre die Rolläden
I am still struggling with the settings to make it work that some filling words for a complete sentence can be in between of the trigger words.
cheers
D3M
Since I changed the logging the video is a bit outdated. To see the mentioned text simple change the config option:
LOGLEVEL = logging.INFO
Or even better, use the „-v“ option to see whenever SOPARE listens to something. As SOPARE starts after a certain THRESHOLD any loud enough sound can trigger the training and your word comes in later which means you get garbage training upfront and therefore unreliable recommendations/recognition.
In terms of your struggling: SOPARE starts after a certain TRESHOLD is reached. Let’s say that you say: „HAL, you are a bad computer, turn out the light“. The whole sentence takes maybe around 4 seconds. If you want to process all the words the config option MAX_TIME must match this timeframe. But, as you make natural stops after „HAL“ and „computer“, the analysis breaks this already in parts like:
1) HAL
2) you-are-a-bad-computer
3) turn-out-the-light
It is possible that some trigger words are detected within the above parts. You need to make sure that SOPARE is able to detect the silence between the words and „tokenize“ is correctly. There are several values affecting this but I would start with LONG_SILENCE. The faster you speak the lower must be the value – but lower values can mess up your learning process and therefore the recognition. I have to admit that the current „tokenizer“ is far from perfect (as written in the readme: „Word separation is not perfect“). You can try to add your logic into the bash script. The bash script receives all recognitions and executes if the trigger words appear in a certain order in a specific time…
Hope that helps a bit.
Hi,
I’m making more and more progress with this. It’s soo nice. 🙂 Can you tell me please how to filter log messages out?
WARNING:sopare.recorder:stream read error [Errno Input overflowed] -9981
WARNING:sopare.recorder:stream read error [Errno Input overflowed] -9981
WARNING:sopare.recorder:stream read error [Errno Input overflowed] -9981
WARNING:sopare.recorder:stream read error [Errno Input overflowed] -9981
….
Not sure why this happens now again and again but it’s flodding my console and makes everything very confusing.
Cheers
D3M
Yeah, this pyaudio issue is annoying and somehow RPi related…I get this on all my RPi systems. Anyway, like I stated before, this issue affects the accuracy at a minimal level – this means the practical effect can be ignored or at least mitigated by using more liberal similarity/distance values.
To get rid of the messages you need to either turn the log level back to ERROR or you can comment out/remove the lines causing the message in the file sopare/recorder.py … maybe in the future I’ll add some individual loglevels for each class for more flexibility. Adding this to my TODO list 😉
However, it is fantastic to read that you are making progress 🙂
bishoph you rock! 🙂
I’ll try later to filter this out. Because I really don’t need that flooding.
I have a future request for you. I think this could help all people who will use this for the finetuning.
In one of the videos I saw that you played with the values for example of
MIN_LEFT_DISTANCE = 0.5
MIN_RIGHT_DISTANCE = 0.4
For finetuning this you started SOPARE with -l -v and checked the values which were shown on the screen. For myelf most of the values don’t tell me anything, since I dont know exactlywhich value reflects the settings in the config file. Is it possible that you can parse that values and make it more user friendly to see this values?
So my guess is, when you have like three learned words and only one of them has false positives, it would be awesome to see all the values in the log which reflect exactly the settings which can be finetuned. At the moment I am trying by myself to parse the values which are interesting for me to finetune the settings in the config. But due my lack of python knowledge it’s not that easy. So in short: Filter all not needed information of the verbose mode out and show only the values which can be used for finetuning.
Keep up the good work!
Cheers
D3M
Thanks :“>
I’ll add your request to my TODO list and see when and how it can be implemented.
Short update: the issue „[Errno Input overflowed] -9981“ should no longer appear with SOPARE version >= 1.4.3. I’ve tested several microphones in combination with Raspian Jessie and Stretch. The conditions to solves this are to use the recommendations from the „python test/test_audio.py“ test class. There is one exception on Raspbian Stretch, where the audio stream fails continuously. For environments where this behavior for whatever reason appears, I’ve added an experimental option to re-create the stream. This works pretty well and is for the time being a workaround until the root cause is known and can be fixed.
ohh damn…. im not very familiar with this wordpress stuff… it cut the code of the bash script
#!/bin/bash
if [ $1 == „an“ ]
then
send „your socket-code“ „socket number“ 1
exit 0
elif [ $1 == „aus“ ]
then
send „your socket-code“ „socket number“ 0
exit 0
else
exit 0
fi
okay one more correction. it cut the „<" of the examples, too
Examples:
1. "HAL" mach/schalte das "Licht" "an/aus"
2. "HAL" du bist ein böser Computer, nun mach das "Licht" "an/aus"
2. "HAL" fahre die Rolläden "hoch/runter"
How can I add code here? like "
Use a
<pre>
Some code
</pre>
https://codex.wordpress.org/Writing_Code_in_Your_Posts
Hi.
I wrote a small bash script for making the learning process a little bit easier for me. Since I’m having still big issues with the accuracy. I thought I could share the script. Maybe it’s somehow usefull for you folks.
It’s not perfect for deleting a fautly record, but in my case it fits. Maybe I’ll update the script later. Let’s see
Cheers
D3M
#!/bin/bash
######################
# define variables #
######################
# path to sopare.py
SOPARE=/home/pi/programs/sopare/sopare.py
# set initial counter to vaule of 1
COUNTER=1
# set path to dict directory of SOPARE
DIR=/home/pi/programs/sopare/dict
# user input
read -p „Which Word do you want to learn? “ WORD
read -p „How often do you want to train? “ COUNT
# latest file function to remove faulty recordings
latest() { local file latest; for file in „${1:-.}“/*; do [[ $file -nt $latest ]] && latest=$file; done; rm -f — „$latest“;}
###############
# do the loop #
###############
while [ $COUNTER -le $COUNT ]
do
$SOPARE -v -t $WORD
((COUNTER++))
read -p „Hit any key to proceed or [r] to remove last faulty record: “ INPUT
if [ „$INPUT“ = „r“ ]
then
latest $DIR
echo -e „\nRecent faulty file deleted“
((COUNTER–))
fi
if [ $COUNTER -le $COUNT ]
then
echo „Prepare for next record in 5“
sleep 1
echo „Prepare for next record in 4“
sleep 1
echo „Prepare for next record in 3“
sleep 1
echo „Prepare for next record in 2“
sleep 1
echo „Prepare for next record in 1“
sleep 1
else
echo „Record done“
exit 0
fi
done
Hi,
great work you’ve done with this project!
I am trying to set up sopare but it keeps crashing as soon as the sound goes over the threshold.
Can you help me with that?
Here is the output when i try to use ./sopare.py -l -v:
sopare 1.4.0
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM cards.pcm.rear
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM cards.pcm.center_lfe
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM cards.pcm.side
ALSA lib confmisc.c:1281:(snd_func_refer) Unable to find definition ‚cards.bcm2835.pcm.surround51.0:CARD=0‘
ALSA lib conf.c:4528:(_snd_config_evaluate) function snd_func_refer returned error: No such file or directory
ALSA lib conf.c:5007:(snd_config_expand) Evaluate error: No such file or directory
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM surround21
ALSA lib confmisc.c:1281:(snd_func_refer) Unable to find definition ‚cards.bcm2835.pcm.surround51.0:CARD=0‘
ALSA lib conf.c:4528:(_snd_config_evaluate) function snd_func_refer returned error: No such file or directory
ALSA lib conf.c:5007:(snd_config_expand) Evaluate error: No such file or directory
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM surround21
ALSA lib confmisc.c:1281:(snd_func_refer) Unable to find definition ‚cards.bcm2835.pcm.surround40.0:CARD=0‘
ALSA lib conf.c:4528:(_snd_config_evaluate) function snd_func_refer returned error: No such file or directory
ALSA lib conf.c:5007:(snd_config_expand) Evaluate error: No such file or directory
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM surround40
ALSA lib confmisc.c:1281:(snd_func_refer) Unable to find definition ‚cards.bcm2835.pcm.surround51.0:CARD=0‘
ALSA lib conf.c:4528:(_snd_config_evaluate) function snd_func_refer returned error: No such file or directory
ALSA lib conf.c:5007:(snd_config_expand) Evaluate error: No such file or directory
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM surround41
ALSA lib confmisc.c:1281:(snd_func_refer) Unable to find definition ‚cards.bcm2835.pcm.surround51.0:CARD=0‘
ALSA lib conf.c:4528:(_snd_config_evaluate) function snd_func_refer returned error: No such file or directory
ALSA lib conf.c:5007:(snd_config_expand) Evaluate error: No such file or directory
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM surround50
ALSA lib confmisc.c:1281:(snd_func_refer) Unable to find definition ‚cards.bcm2835.pcm.surround51.0:CARD=0‘
ALSA lib conf.c:4528:(_snd_config_evaluate) function snd_func_refer returned error: No such file or directory
ALSA lib conf.c:5007:(snd_config_expand) Evaluate error: No such file or directory
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM surround51
ALSA lib confmisc.c:1281:(snd_func_refer) Unable to find definition ‚cards.bcm2835.pcm.surround71.0:CARD=0‘
ALSA lib conf.c:4528:(_snd_config_evaluate) function snd_func_refer returned error: No such file or directory
ALSA lib conf.c:5007:(snd_config_expand) Evaluate error: No such file or directory
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM surround71
ALSA lib confmisc.c:1281:(snd_func_refer) Unable to find definition ‚cards.bcm2835.pcm.iec958.0:CARD=0,AES0=4,AES1=130,AES2=0,AES3=2‘
ALSA lib conf.c:4528:(_snd_config_evaluate) function snd_func_refer returned error: No such file or directory
ALSA lib conf.c:5007:(snd_config_expand) Evaluate error: No such file or directory
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM iec958
ALSA lib confmisc.c:1281:(snd_func_refer) Unable to find definition ‚cards.bcm2835.pcm.iec958.0:CARD=0,AES0=4,AES1=130,AES2=0,AES3=2‘
ALSA lib conf.c:4528:(_snd_config_evaluate) function snd_func_refer returned error: No such file or directory
ALSA lib conf.c:5007:(snd_config_expand) Evaluate error: No such file or directory
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM spdif
ALSA lib confmisc.c:1281:(snd_func_refer) Unable to find definition ‚cards.bcm2835.pcm.iec958.0:CARD=0,AES0=4,AES1=130,AES2=0,AES3=2‘
ALSA lib conf.c:4528:(_snd_config_evaluate) function snd_func_refer returned error: No such file or directory
ALSA lib conf.c:5007:(snd_config_expand) Evaluate error: No such file or directory
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM spdif
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM cards.pcm.hdmi
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM cards.pcm.hdmi
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM cards.pcm.modem
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM cards.pcm.modem
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM cards.pcm.phoneline
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM cards.pcm.phoneline
ALSA lib confmisc.c:1281:(snd_func_refer) Unable to find definition ‚defaults.bluealsa.device‘
ALSA lib conf.c:4528:(_snd_config_evaluate) function snd_func_refer returned error: No such file or directory
ALSA lib conf.c:4996:(snd_config_expand) Args evaluate error: No such file or directory
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM bluealsa
ALSA lib confmisc.c:1281:(snd_func_refer) Unable to find definition ‚defaults.bluealsa.device‘
ALSA lib conf.c:4528:(_snd_config_evaluate) function snd_func_refer returned error: No such file or directory
ALSA lib conf.c:4996:(snd_config_expand) Args evaluate error: No such file or directory
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM bluealsa
Cannot connect to server socket err = No such file or directory
Cannot connect to server request channel
jack server is not running or cannot be started
JackShmReadWritePtr::~JackShmReadWritePtr – Init not done for -1, skipping unlock
JackShmReadWritePtr::~JackShmReadWritePtr – Init not done for -1, skipping unlock
INFO:root:checking for plugins…
DEBUG:root:loading and initialzing plugins/print
DEBUG:sopare.recorder:{‚index‘: 0L, ’name‘: u’ALSA‘, ‚defaultOutputDevice‘: 5L, ‚type‘: 8L, ‚deviceCount‘: 7L, ‚defaultInputDevice‘: 2L, ’structVersion‘: 1L}
DEBUG:sopare.recorder:SAMPLE_RATE: 48000
DEBUG:sopare.recorder:CHUNK: 512
INFO:sopare.recorder:start endless recording
INFO:sopare.worker:worker queue runner started
INFO:sopare.buffering:buffering queue runner
INFO:sopare.processing:starting append mode
DEBUG:sopare.filter:New window!
Process buffering queue:
Traceback (most recent call last):
File „/usr/lib/python2.7/multiprocessing/process.py“, line 258, in _bootstrap
self.run()
File „/home/pi/sopare/sopare/buffering.py“, line 44, in run
self.proc.check_silence(buf)
File „/home/pi/sopare/sopare/processing.py“, line 76, in check_silence
self.prepare.prepare(buf, volume)
File „/home/pi/sopare/sopare/prepare.py“, line 127, in prepare
self.tokenize(meta)
File „/home/pi/sopare/sopare/prepare.py“, line 52, in tokenize
self.filter.filter(self.buffer, meta)
File „/home/pi/sopare/sopare/filter.py“, line 133, in filter
if (shift_fft != None and (hasattr(sopare.config, ‚FFT_SHIFT‘) and sopare.config.FFT_SHIFT == True)):
ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
INFO:sopare.recorder:Buffering not alive, stop recording
INFO:sopare.recorder:stop endless recording
The same error appears when I try to use ./sopare -t „test“
Did I configure something wrong or set up the environment the wrong way? I know about the alsa warnings, but the error doesn’t really seem like it has something todo with the system. But I might be wrong..
Any help is apreciated!
Thanks in advance!
Ringo
Hi Ringo,
this issue is fixed since quite some time in the testing branch. You can either switch to the testing branch or wait a little bit as I’m going to merge the testing branch (and start a „git pull“ after the merge) within the next couple of days.
I also recommend to clean you alsa.conf file to avoid cluttered output each time you start SOPARE 😉
Have fun and happy voice controlling!
Hi,
thanks very much for your fast response.
I tried to switch to the testing branch but the problem also persists here.
Although the code is a bit different the program still crashes on the same line.
Here is the output from ./sopare.py -l -v:
sopare 1.4.9
ALSA lib confmisc.c:1281:(snd_func_refer) Unable to find definition ‚defaults.bluealsa.device‘
ALSA lib conf.c:4528:(_snd_config_evaluate) function snd_func_refer returned error: No such file or directory
ALSA lib conf.c:4996:(snd_config_expand) Args evaluate error: No such file or directory
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM bluealsa
ALSA lib confmisc.c:1281:(snd_func_refer) Unable to find definition ‚defaults.bluealsa.device‘
ALSA lib conf.c:4528:(_snd_config_evaluate) function snd_func_refer returned error: No such file or directory
ALSA lib conf.c:4996:(snd_config_expand) Args evaluate error: No such file or directory
ALSA lib pcm.c:2495:(snd_pcm_open_noupdate) Unknown PCM bluealsa
Cannot connect to server socket err = No such file or directory
Cannot connect to server request channel
jack server is not running or cannot be started
JackShmReadWritePtr::~JackShmReadWritePtr – Init not done for -1, skipping unlock
JackShmReadWritePtr::~JackShmReadWritePtr – Init not done for -1, skipping unlock
INFO:sopare.analyze:checking for plugins…
DEBUG:sopare.analyze:loading and initialzing plugins/print
DEBUG:sopare.audio_factory:#### Default input device info #####
DEBUG:sopare.audio_factory:defaultSampleRate: 44100.0
DEBUG:sopare.audio_factory:defaultLowOutputLatency: 0.0087074829932
DEBUG:sopare.audio_factory:defaultLowInputLatency: 0.00868480725624
DEBUG:sopare.audio_factory:maxInputChannels: 1
INFO:sopare.worker:worker queue runner started
DEBUG:sopare.audio_factory:structVersion: 2
DEBUG:sopare.audio_factory:hostApi: 0
DEBUG:sopare.audio_factory:index: 2
DEBUG:sopare.audio_factory:defaultHighOutputLatency: 0.0348299319728
DEBUG:sopare.audio_factory:maxOutputChannels: 2
DEBUG:sopare.audio_factory:name: USB Audio Device: – (hw:1,0)
DEBUG:sopare.audio_factory:defaultHighInputLatency: 0.0348299319728
INFO:sopare.buffering:buffering queue runner
DEBUG:sopare.recorder:SAMPLE_RATE: 48000
DEBUG:sopare.recorder:CHUNK: 512
INFO:sopare.recorder:start endless recording
INFO:sopare.processing:starting append mode
DEBUG:sopare.filter:New window!
Process buffering queue:
Traceback (most recent call last):
File „/usr/lib/python2.7/multiprocessing/process.py“, line 258, in _bootstrap
self.run()
File „/home/pi/testing_sopare/sopare/buffering.py“, line 43, in run
self.proc.check_silence(buf)
File „/home/pi/testing_sopare/sopare/processing.py“, line 74, in check_silence
self.prepare.prepare(buf, volume)
File „/home/pi/testing_sopare/sopare/prepare.py“, line 125, in prepare
self.tokenize(meta)
File „/home/pi/testing_sopare/sopare/prepare.py“, line 50, in tokenize
self.filter.filter(self.buffer, meta)
File „/home/pi/testing_sopare/sopare/filter.py“, line 130, in filter
if (shift_fft != None and self.cfg.hasoption(‚experimental‘, ‚FFT_SHIFT‘) and self.cfg.getbool(‚experimental‘, ‚FFT_SHIFT‘) == True):
ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
INFO:sopare.recorder:Buffering not alive, stop recording
INFO:sopare.recorder:stop endless recording
Also the same still happens with ./sopare.py -t „Test“
Also on another note the testing function python test/test_audio.py crashes on startup (if you don’t know already 🙂 ):
Traceback (most recent call last):
File „test/test_audio.py“, line 31, in
import sopare.audio_factory
ImportError: No module named audio_factory
Thanks!
PS: Would it be easier for you if I submitted this on the issues page on your github?
Yes, please create an issue on GitHub if you find a bug. This particular issue seems to be related to Numpy >= 1.13 and it should be fixed by changing the line 130 to something like this:
if ((shift_fft is not None) and self.cfg.hasoption('experimental', 'FFT_SHIFT') and self.cfg.getbool('experimental', 'FFT_SHIFT') == True):Please note that I can’t test this as I don’t have this specific Numpy version. So it would be perfect if you:
1) File a new SOPARE issue on GitHub
2) Test if (and possible how) the code must look like to avoid the issue (maybe the above code does the trick)
3) Report back or create a pull request
Thanks for reporting!
Hi,
First of all, thank you, this is what I had been searching for a long time.
I think I’ve read everything you’ve written already, but I can’t get it to do what I want.
I’d like to detect the doorbell sound, but instead of using a Raspberry Pi with a mic, I want to use my Ubuntu 14.04 server using a video network stream as sound input, as I read in https://github.com/bishoph/sopare/issues/8
I think I solved this part with the following commands on the server:
mplayer -novideo rtsp://192.168.0.37:554/unicast
pactl list short sources
pactl set-default-source auto_null.monitor
With them I play the stream audio and set the output monitor as default input, simulating a mic.
I’m using the testing branch of SOPARE, and this is the sound I want to detect (recorded with „./sopare.py -w samples/timbre_puerta.raw -~“):
https://www.dropbox.com/s/4ztm4vxlqkmqal7/timbre_puerta.raw?dl=0
If you open it with Audacity (with Import/Raw Data, Signed 16 bit PCM, Little endian, 1 Channel) it plays correctly, and if you do a spectrum analysis (Analyze/Plot spectrum), you can see frecuencies up to about 3500 Hz, so I changed HIGH_FREQ in default.ini accordingly. That’s the only value I changed.
In order for sopare.py (testing) to work, I had to edit filter.py and change line 61 to „progessive += progessive * 0“ (that’s the value I saw for PROGRESSIVE_FILTER in master version).
I trained SOPARE with five repetitions of the sound, and when I run „sopare.py -l“ I only get false positives, but no correct hits.
I can’t get the .raw samples in dict to play with Audacity, is this normal? Is there a way to record the samples used for training (to review or reuse them)?
Sometimes while training I got this error (even though the .raw file was created):
Traceback (most recent call last):
File „/usr/lib/python2.7/multiprocessing/queues.py“, line 266, in _feed
send(obj)
IOError: [Errno 32] Broken pipe
Is this correct?
If I run SOPARE with -v it gives waaaaay too much information to post, here you have it:
https://www.dropbox.com/s/y3t8l8jjvbfszhb/sopare_debug.txt?dl=0
Which values would you recommend for default.ini? What else should I do?
Thanks! This project is awesome!!!
Jose Jaime
Hola Jose,
thanks for your comment and great that you like SOPARE! First, I have no idea about your environment and if the stream can be „simulated“ like you did it. But if the answer is yes this is phenomenal! I would like to ask if you could comment on https://github.com/bishoph/sopare/issues/8 and describe what you did for other users. Thanks in advance.
Now about your doorbell recognition. I think a doorbell is not only one frequency and I’ve no clue about the time but when I take my doorbell as reference the sound is longer than 1 second and the frequency range is from zero into the thousands. Of course there is a dominant frequency if you record smaller chunks (this is what SOPARE does) and you can configure the precision to make use of it. I would play with the values between 0 and lets say 4000 (LOW_FREQ = 20 and HIGH_FREQ = 4000). SOPARE analysis everything between this frequencies and in addition also extracts the dominant frequency for each chunk. Also make sure you record the whole doorbell sound (in terms of time!). Adjust the times (MAX_SILENCE_AFTER_START = 1.4, MAX_TIME = 2.4, LONG_SILENCE = 50) accordingly. Use a higher value for the LONG_SILENCE first as you have one doorbell and not different words that needs to be recognized. This should also avoid the broken pipe error you get.
Now you should test several CHUNKS sizes. Play with bigger values (I would start with 4096). This size represents in reality the time for the chunk. If the doorbell sound takes 1 second and you get 4 chunks each chunk represents around 1/4 second – no exactly but you know what I mean. It’s possible that higher chunks work better for some sounds. Play around with it and check where you get the best results.
Try also to use several recognition models like:
SIMILARITY_NORM = 1
SIMILARITY_HEIGHT = 0
SIMILARITY_DOMINANT_FREQUENCY = 0
then test the difference by leveraging only the dominant frequency:
SIMILARITY_NORM = 0
SIMILARITY_HEIGHT = 0
SIMILARITY_DOMINANT_FREQUENCY = 1
You should be able to find a model that fits best for you and your environment. In my case it’s mostly a mix but as I want to recognize voice commands and spoken words this could be different for your requirements and needs.
Hope this helps you to get started. Have fun! Saludos!
Hi,
Is there a way to record the samples used for training so that I can be sure that I recorded the whole sound? With the network stream I have a 2-5 second delay and I can’t be sure 100%.
Also, it would be handy to train SOPARE whith pre-recorded sounds, so that I don’t have to be ringing the doorbell every time I change an option.
The values that you recommended me were a starting point or did you try with the recorded doorbell sound I posted (https://www.dropbox.com/s/4ztm4vxlqkmqal7/timbre_puerta.raw?dl=0)?
Thanks,
Jose Jaime
Hi Jose.
You can train and record a sound within the same command:
My recommendations were made on best case practice theory, I did not used you recorded ones.
You need to find the optimal „THRESHOLD“ and some good values for „MIN_PROGRESSIVE_STEP“ and „MAX_PROGRESSIVE_STEP“. But even with the default values used in the testing branch you should be able to get some quite good results. But of course I have no clue about the environment and potential interferences so this is just a wild wild guess 😉
Saludos!
Hi Martin,
I can’t get it to work. I’ve been tweaking many settings for all the afternoon and I can’t even get it to generate the .raw files in dict/ now. I have run it with -v, but I don’t know what debug output means.
Could you do me a favor and take a look and these samples:
https://www.dropbox.com/sh/d3rxm8ekqjljklv/AACW3bnm9sECHxLNOy4GjdJRa?dl=0
and recommend some values for them?
If you have a Linux system with PulseAudio (it seems that in the Raspberry it isn’t installed by default), you can play the .wav files and pipe them to the mic just as I did with the video network stream:
pactl list short sources
pactl set-default-source auto_null.monitor
mplayer sample.wav
(This is what I’m doing to train SOPARE with prerecorded samples).
Thanks a million!!!
Please provide the configuration you used to train and record the raw files…it seems as the stream cuts off before the analysis kicks in which means that either some timing values require some tweaking or the stream just drops of too early.
Was bedeutet es, wenn man das gesprochene Aufzeichnen kann?
Also mit dem ./sopare.py -w Befehl? Was wird damit ausgeführt?
Außerdem würde ich gerne wissen für was die samples und tokens da sind bzw.
ob man damit arbeiten muss/sollte.
Im Voraus schon mal Danke
Mittels „write“ oder „-w“ werden die Rohdaten gespeichert. Ich benutze die Option meistens zum Testen. Dazu trainiere ich ein Wort und speichere einige Versionen mittels „-w“ ab. Dann kann ich unabhängig von Umgebungsgeräuschen oder mitten in der Nacht und ohne andere in den Wahnsinn zu treiben mittels „-r“ den gespeicherten Input testen.
In die Verzeichnisse „samples“ und „tokens“ werden Dateien abgelegt, z.B. wenn man die Option „-wave“ nutzt. Die Verzeichnisse sind nicht unbedingt notwendig, aber wenn man alle Funktionen nutzt und die Verzeichnisse nicht vorhanden sind kommt halt ein Fehler.
Hi,
I can’t tell you the configuration used to record and train as I have changed many values, I didn’t know the raw files were dependant on the config.
Anyway, I’ve given a step back. I also wanted to try pyAudioAnalysis (https://github.com/tyiannak/pyAudioAnalysis) and to make it work I uninstalled the dependencies with apt-get and reinstalled them with pip (the installed ones with apt-get didn’t work with pyAudioAnalysis), and now, SOPARE doesn’t work. The unit and audio tests work ok, but when I try to train a word (with default values, both in master and testing), I’m getting this error as soon as it detects a sound above the thereshold:
Process buffering queue:
Traceback (most recent call last):
File „/usr/lib/python2.7/multiprocessing/process.py“, line 258, in _bootstrap
self.run()
File „/home/jjaime/nas/sopare-master/sopare/buffering.py“, line 44, in run
self.proc.check_silence(buf)
File „/home/jjaime/nas/sopare-master/sopare/processing.py“, line 76, in check_silence
self.prepare.prepare(buf, volume)
File „/home/jjaime/nas/sopare-master/sopare/prepare.py“, line 127, in prepare
self.tokenize(meta)
File „/home/jjaime/nas/sopare-master/sopare/prepare.py“, line 52, in tokenize
self.filter.filter(self.buffer, meta)
File „/home/jjaime/nas/sopare-master/sopare/filter.py“, line 133, in filter
if (shift_fft != None and (hasattr(sopare.config, ‚FFT_SHIFT‘) and sopare.config.FFT_SHIFT == True)):
ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()
Which is strange, as it doesn’t seem to reference any of the libs.
Any ideas?
Thanks!
Jose Jaime
Hi Jose,
yes, this issue is already fixed but I haven’t got the change to push the fix yet. Will do whenever I’ve some time left. The push will also be a merge to stable version 1.5 so please be patient. Should be done latest mid next week. To get it going you can manually change the code: https://github.com/bishoph/sopare/issues/10
Hi
I’m wondering if this could be used for my project?
I play darts, and when playing i use my RPI on a darts-scorer homepage http://www.pro-darter.com/x01.html and i would like to know if it is possible to say the score and have have sopare enter it for me? It would have to be able to distinguish between around 170 different numbers ranging from 0-180 and then put the score in and hit enter.
Hi, not sure but I wouldn’t use SOPARE for this specific use case. Far too many variations. If the code already runs on a Pi/computer you have the scores as real values which means I don’t see the need of transforming them back and forth to audio and convert them back…but maybe I don’t understand the whole architecture 😉
It was just to avoid having to enter the score with the keyboard all the time 🙂
Thanks for your answer though.
Hi!
Can I use this to detect particular sounds except voice? I’m thinking of using this on my project that continuously detects chainsaw sound. What parameters do you think should I change? Thank you!
Should work, but depends a lot on the environment and training data. Can’t help much in terms of parameters. Just start with the defaults and see how far you can go. I would recommend to use periodical, recognizable and characteristic sounds for training. Not sure if you can extract something that can identify a chainsaw or different ones but if you can, SOPARE should be able to recognize the sound later on. Have fun 🙂
Hi!
I started using sopare for the said project, however I cannot seem to grasp the idea of the training. If I understand it right, sopare will start training/recording a sound once the threshold is met. But is there a parameter that controls the duration/length of the sound it records?
Thank you!
Hey. Yes, these parameters exists. Imagine a sound level curve like a Gaussian curve where THRESHOLD defines the starting point and the end points are either defined by MAX_SILENCE_AFTER_START or MAX_TIME, whatever hits first. MAX_TIME is the maximal time per sound/word before the analysis starts and MAX_SILENCE_AFTER_START is a kind of soft value when the sound level falls under the THRESHOLD.
hi
thank you for your fast response for every questions
i just want to know the unit of the THRESHOLD? is it a volt? or other means?
Happy to help 🙂
The THRESHOLD defines the power of the audio signal. It’s an numerical value from zero to N and depends on your mic, your environment, your settings and the data while measuring.
thank you very very much for your help.
I am using your project as a basic speech to text platform for my project and i need to understand its basic operations so i asked you too much questions.
please be patient with me.
can you please explain the basic technology for your speech to text conversion from the digital signal processing perspective?
or you can direct me to some references to understand sound pattern recognition please.
Hi. You can read some papers about pattern recognition and you may want to start here:
https://en.wikipedia.org/wiki/Pattern_recognition
Next start to learn about sounds and FFT:
http://www.theparticle.com/cs/bc/mcs/signalnotes.pdf
https://en.wikipedia.org/wiki/Fast_Fourier_transform
And after that you are halfway through 😉
Thank you very much for your attention and fast response
I’ve read the references that you pointed and as I understood that the speech recognition compose of two steps:
feature extraction
and classification
so I just want to know the types of the processes you used in your project
I just want a hint to overcome the all operation
have you used FFT as a feature extraction?
and as I explored your posts, I noticed that at comparison you used LEFT_DISTANCE and RIGHT_DISTANCE , so can you please name the algorithms you used?
is there any similarity between your project and audio fingerprinting technique?
I know that I asked two much questions
please be patient
and thank you again
I wrote answers to some of your questions in my blog posts which means that the information is
available.
I would answer the question about fingerprint technique with a yes“ even if some details may say no 😉
Hello,
I’m having trouble getting sopare to recognize two words at once. At the moment it’s doing a pretty fine job of recognizing single words, but when I try to say two words at once, it will sometimes just recognize one or it will recognize one of the two but have a blank entry for the other word.
For example, here is a sample of the printed output of the readable_results while trying to get it to recognize me saying „quit sopare“:
[]
[“, u’sopare‘]
[]
[“, u’quit‘] <—(here I tried saying "sopare quit")
[]
[u'quit']
[]
[u'quit', '']
[]
['', u'sopare']
More often than not it seems to be recognizing that there are two words being said, as it will often register that other word with a blank '', but still only recognizes one of the said words. Any recommendations to fix this? Thank you.
I’m using multi word commands to control stuff in my home. I trained each word individually until it gets recognized nearly perfect. Saying two words one after another cuts sometimes characters or smears them acoustically together. I train the words accordingly. Try to decrease the left and right distances and maybe choose a less restrictive FILL_RESULT_PERCENTAGE. To get started, even turn off the STRICT_LENGTH_CHECK. You will get more false positives for sure. Tweak then until you get decent results.
Hope that helps as environment, words and lots of other stuff is relevant and affects the results.
Does Sopare need an usb microphone?
SOPARE uses pyAudio as sound interface. pyAudio is the bridge to PortAudio which is the interface to the platform specific implementation layer. On the Raspberry Pi ALSA is used. This said, SOPARE is quite far away from any real hardware and just reads data from a source. You can define and use any source that is supported by the different layers, interfaces and implementations. This said, the answer to your question is no.
For further information here is a list of supported cards by ALSA: https://alsa.opensrc.org/Sound_cards
Help me!
My mic usb PnP not working with Sopare 🙁
Tks so much!!
If you want help you have to be supportive. Provide useful information what you did and why it is not working. Best with error messages and/or how to reproduce instructions. The alternative is me looking into the crystal ball and say meh 😉
Hello i have several questions i hope you can answer me
What is the Marginal value determine
How does progressive step work do you just take the mean of all the step value and combine it into one?
And does min left and right distance use to determine matching
Thank you very much
As the determination of the marginal value changed over time and will change in the future I can safely say that rough characteristics are referred to calculate this value. Progressive steps creates the matrix norm by using numpy.linalg.norm. As described in the blog, left and right distance values are helpful to eliminate false positives. And all the details are of course in the code 😉
Can you tell me what left and right distance measure to determine false positive? Thank you.
Not sure if I understand the question. HOwever, I would start low and increase slowly until the results are decent…
Um can you tell me what values being compared to determine the recognized word is it Euclidean distance, or is it other characteristics of the signal?
Based on the used configuration it’s a combination of different characteristics just as explained in the blog posts 😉
Is the Hanning length also the characteristic length?
The Hanning length config value is a Boolean.
Hi Bishoph, how are you? Is it possible to instead input words through a microphone, input via audio files?
Let’s cross check. You can store input in files and use them for training…
Thanks for putting this together, it seems really cool, and I think its just what I need for my project.
I have encountered a few snags Im hoping you can help me sort out.
I have taught it low, medium, high, off and gandalf. When I first start it up, it works great. It gets the first 10 to 15 words dead on. Then it gets worse and worse. Gandalf starts outputting low, medium outputs off, eventually I cant get it to respond at all. Even if I shout at the mic I don’t even get „[ ]“.
I also get a broken pipe error every 3 or 4 training attempts. I always delete the .raw file that is generated from those attempts. I also get a long string of alsa lib and „jackshmreadwrite“ „jack server is not running“ messages when I start it up. I have seen other people post about these and it seems like you mostly just ignore these messages, are they not important?
Hey. You are welcome! Without more details I can only guess. Seems the load is too high as it becomes worse over time. Check the load while running e.g. with the command „top -d 1“ or something similar. Could be that the input sensitivity gives much content together with many training words to compare. I would start with one or two words training and try to get stable results also for longer periods. Also adjust the „THRESHOLD“ to only trigger when you say one of your trained words. While it runs have an eye on the system and the load. Then add more training and see what happens. Other than that, it could nearly be everything 😉
python immediate takes up 99-101% cpu. Also, it doesn’t recover when I turn it off and back on. The first time I turned it on it did great for the first minute and 10-15 words. If I turn it on now it immediately acts up and doesn’t recognize anything. Is there something it holds over, or changes while it is listening?
I guess I should mention, when I tried to use it originally it said no module named „ConfigParser“. After looking into it, I found out that in python 3 they changed it to „configparser“, so I run all my commands via python 2.7.
So:
python2.7 sopare.py -l
Ok, apparently its inconsistent. It didn’t do well this time, it got the first word wrong, then a couple right, it seems like I have to annunciation more than I did before, and then after about 30 seconds it went up to 100%cpu and stopped working.
Hey,
first of all I would like to congratulate you on your excellent job, very nice software.
I’ve watch your videos of tuning SOPARE and I have a question or suggestion.
Would’t it be better for recognizing human voice with a frequenzy range of 300Hz to 3,4KHz as is usual on a telephone line?
Greetings
Thank you very much!
Regarding the frequencies: As I am a male with a lower pitch the frequencies are perfect for my voice. If you want to cover woman and kids, you obviously need higher frequencies and a wider range. Just test it out what fits best for you and your environment. In my case the higher frequencies don’t make a difference in precision and can easily be ignored. This also results in smaller data and better performance…